[paper review] EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos (1)
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos 논문 리뷰 (1)
현재 시각 22:50, 저는 학교 연구실에서 VLA 논문을 정독하고 있습니다. 어쩌다 읽게 되었나?! 계절학기 연구수업에서 준 논문입니다. 왜 그 수업을 들었나?! 멀티모달리티에 DEEPDIVE를 하고 싶었기 때문입니다. 모레 크리스마스에 수영장 가기 앞서 예습할 겸 VLA에 다이빙해보려 합니다.
EgoVLA의 ego는 데이터셋의 Egocentric한 특징에서 유래했습니다. Egocentric (형) 자기중심적인. 1인칭 시점에서 촬영된 영상 데이터셋을 활용한 부분과 관련이 있는 거 같습니다. 본 논문은 로봇이 실제로 등장하는 데이터의 확보가 어렵다는 문제를 ‘실제 인간의 영상 데이터’를 활용하는 방법으로 풀고자 했습니다.
오늘은 논문 목차 중
- Introduction
- Related Work
- Learning Manipulation Skills from Ego-centric Human Videos
세 파트를 톺아보겠습니다.
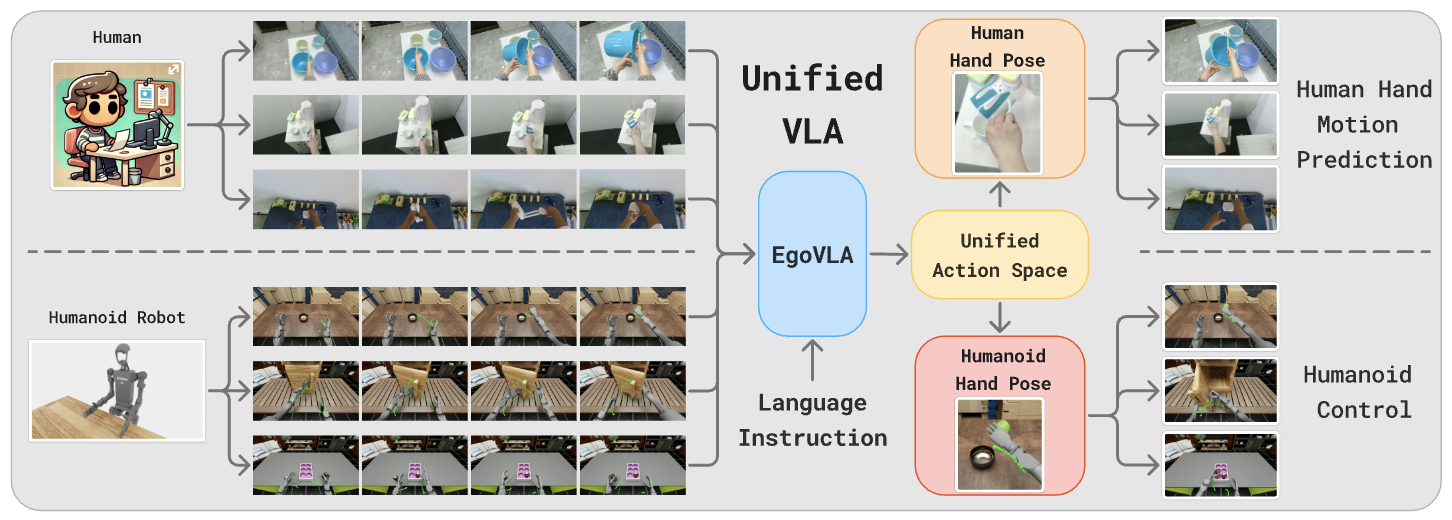
먼저 전체 EgoVLA 파이프라인에 대한 한 줄 요약!
VILA는 NVIDIA에서 만든 범용 비전-언어 모델인데, 이 VILA 계열 모델(NVILA-2B)을 backbone VLM으로 써서 그 위에 action head만 얹어 VLA로 확장한 것
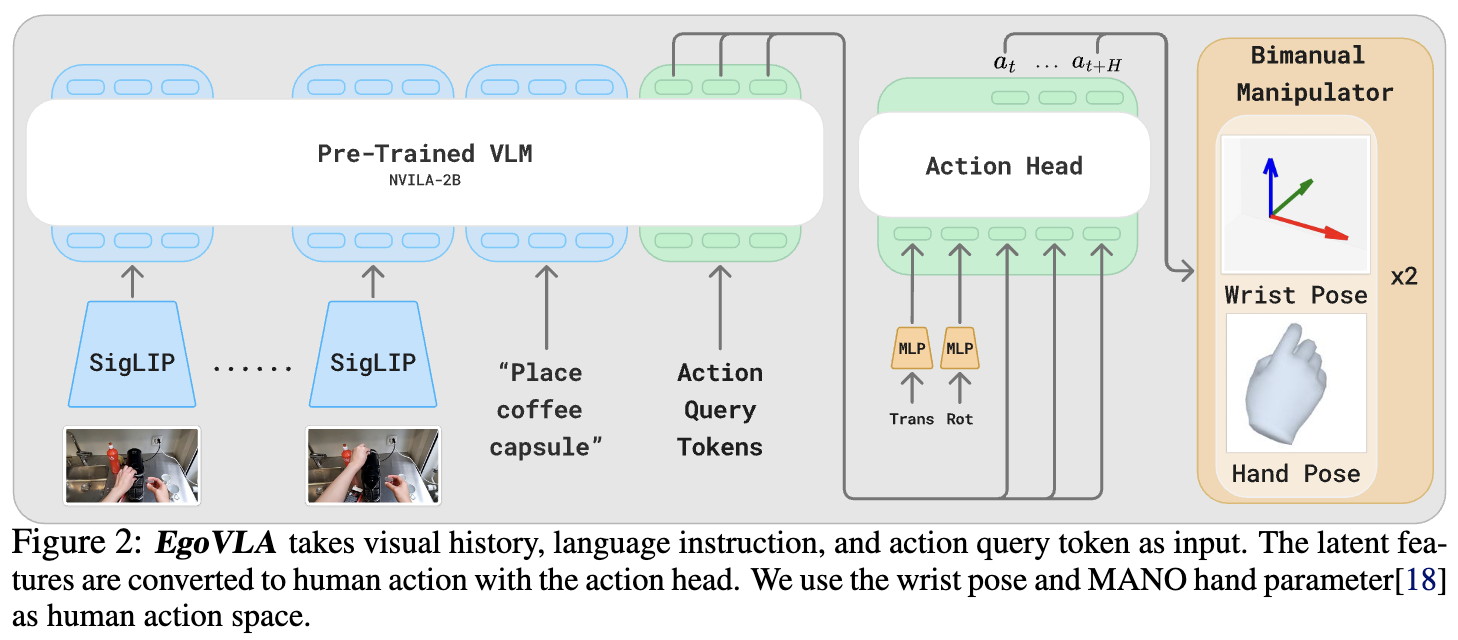
3장에서는 EgoVLA의 자세한 구조를 이야기합니다. Fig2의 EgoVLA는 크게 두 부품으로 구성되는데, 우선 Pre-trained VLM은 vision, language, action 세 모달리티에 대응하는 정보들을 입력으로 받습니다. 입력은 어떤 내용을 담아야 할까요?
우리 EgoVLA 모델은 자연어의 명령문을 듣고 이를 수행하기 위한 동작을 취하고 싶습니다. 그러기 위해선 “커피 캡슐을 내려놓아”라는 language instruction과 커피캡슐 위치를 파악할 수 있는 visual observation이 필요합니다.
Fig2의 또 다른 입력 Action Query Token이 의아할 수도 있습니다. 저는 ‘어떻게 벌써 action 정보를 넣어주지?’라는 생각에 직관과 동떨어진 느낌을 받았는데 저만 그랬던 걸까요?^^
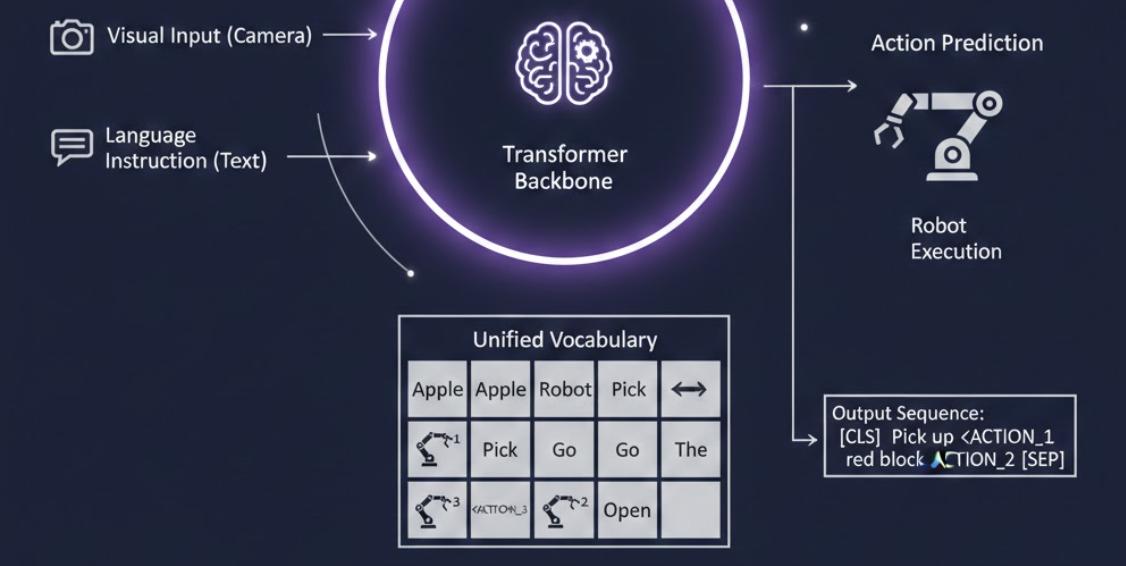
Action Query Token의 정체를 알기 전에 VLA 모델에서 action 정보가 어떻게 처리되는지 알면 좋습니다. VLA는 자연어와 모션 두 모달리티를 같은 임베딩 공간에 두려고 합니다. 흔히 말뭉치 집합 corpus나 단어장 dictionary에 action 정보가 삐집고 들어간 모습을 상상해보면 됩니다. 극 대본에 비유해볼 수도 있습니다. 대본은 대사와 행동 지침이 한 줄에 모두 적혀 있죠. 이로써 VLA는 다음에 올 단어를 확률적으로 고르듯이 단어와 모션을 고르면 됩니다. 예를 들어 자연어 ‘오른쪽’ ‘왼쪽’ 등 방향을 나타내는 자연어 근방에 모션 정보가 올 확률이 높겠죠?
다시 action query token으로 넘어오자면 action query token은 비전+이미지 정보 뒤에 빼꼼 붙습니다. 하지만 빈 상태로 붙어 VLM이 알아서 context에 맞게 채워주기를 기다립니다. 이렇게 채워진 action token은 아직은 로봇이 알아듣지 못하는, latent space에 있다고 할 수 있습니다. 그러나 시각/의미/동작 삼쌍 정보가 압축적으로 들어가 있습니다.
이제 두번째 부품, Action Head를 살펴볼 차례입니다. action head는 VLM이 출력한 action token을 입력으로 받아 로봇이 알아듣기 더 편하게 변환해줍니다.