[paper review] Unsupervised Domain Adaptation for Ship Classification via Progressive Feature Alignment: From Optical to SAR Images
이번 학기에 인공위성 사진을 다룬 흥미로운 연구 수업이 있어 수강하게 되었습니다. 바로 인공위성이 촬영하는 여러 이미지 종류 중, SAR과 Optical(광학) 이미지 간 도메인 차이를 줄이는 연구입니다.
이 논문은 Optical 위성 이미지의 풍부한 레이블 정보를 활용하여, 레이블이 없는 SAR(Synthetic Aperture Radar) 이미지의 선박 분류 성능을 높이는 비지도 도메인 적응 프레임워크를 제안합니다.
SAR, Optical간 도메인 갭을 줄이는 건 왜 중요할까요? SAR와 Optical 영상의 융합은 서로 다른 특성을 보완해 원격탐사 성능을 높인다는 점에서 중요합니다. Optical 영상은 색상과 분광 정보를 통해 지표의 종류를 파악하는 데 강점이 있지만, 구름이나 야간 환경에서는 활용이 제한된다는 단점이 있습니다. 반면 SAR 영상은 날씨와 시간의 영향을 거의 받지 않고 구조, 거칠기, 수분과 같은 물리적 특성을 관측할 수 있다. 따라서 두 영상을 함께 활용하면 지표를 더 정확하고 안정적으로 이해할 수 있어, 두 모달리티간 도메인 적응과 안정적인 fusion은 중요한 과제가 되었습니다.

- Optical Supervise: 광학 영상으로만 학습된 모델
- SAR supervise: SAR 영상으로만 학습된 모델
- DANN (Domain Adversarial Neural Network): 광학 데이터를 기반으로 SAR 데이터에 적응시키려는 전형적인 UDA 모델
기존 방식의 한계
- SAR, Optical 분포는 서로 많이 다르기 때문에 도메인에 따라 동일한 클래스의 판별 특성 역시 달라질 수 있습니다.
- 클래스 레벨의 정렬이 부재하여 도메인 전체의 분포를 맞추더라도, 광학 데이터의 화물선이 SAR 데이터의 유조선과 잘못 매칭되는 현상이 발생합니다.
- 레이블이 없는 SAR 데이터 내부에서도 같은 종류끼리는 뭉치고(Intraclass Compactness), 다른 종류끼리는 멀어져야(Interclass Separation) 하는데, 기존 방식은 광학 데이터의 가이드에만 의존하다 보니 SAR 도메인 고유의 특징을 놓치게 됩니다.
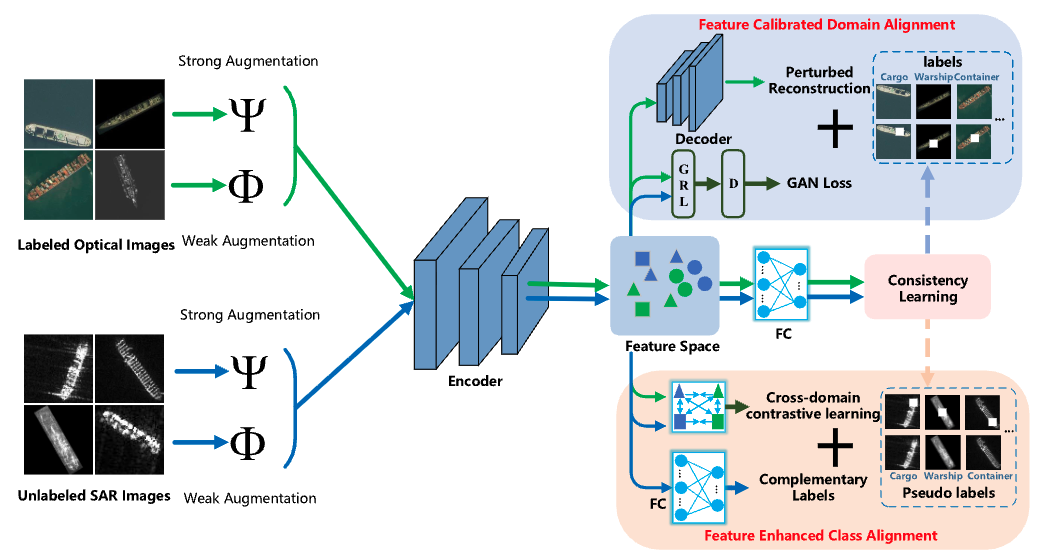
Feature Calibrated Domain Alignment, FCDA
Based on the infrastructure of adversarial-learning-based DIR, FCDA combines the reconstruction and the consistency constraints of different perturbed versions of the same image.
Perturbed Reconstruction and Consistency Constraints
\[\mathcal{L}_{\text{PR}} = \frac{1}{B} \sum_{i=1}^{B} \left( \left\| \mathrm{De}(\mathrm{En}(\Phi(x_i))) - \Phi(x_i) \right\|_2 + \left\| \mathrm{De}(\mathrm{En}(\Psi(x_i))) - x_i \right\|_2 \right)\] \[\mathcal{L}_{\text{PC}} = \frac{1}{B} \sum_{i=1}^{B} \left( H(p_{i,o}^{w}, y) + H(p_{i,o}^{w}, p_{i,o}^{s}) \right)\]Adversarial-Learning-Based DIR Extraction
\[\mathcal{L}_{\text{DIR}}(\mathrm{En}, D, X_{\text{optical}}, X_{\text{SAR}}) = E_{x_{\text{optical}} \sim X_{\text{optical}}} [\log D(\mathrm{En}(x_{\text{optical}}))] + E_{x_{\text{SAR}} \sim X_{\text{SAR}}} [\log(1 - D(\mathrm{En}(x_{\text{SAR}})))].\] \[\mathcal{L}_{\text{FCDA}} = \lambda_{\text{PR}} \mathcal{L}_{\text{PR}} + \lambda_{\text{PC}} \mathcal{L}_{\text{PC}} + \lambda_{\text{DIR}} \mathcal{L}_{\text{DIR}}\]Feature Enhanced Class Alignment, FECA
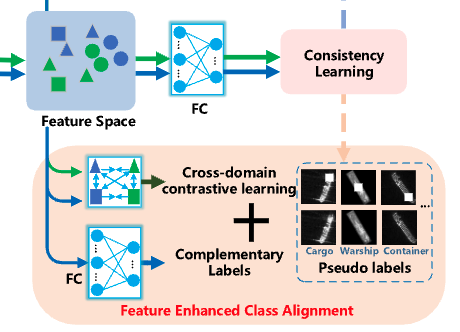
The proposed CDC models the pairwise similarities between two domains to capture fine-grained category alignment, where the class information of SAR images is obtained with pseudo-labels. Complementary labels are introduced to fully exploit unlabeled data.
Cross-Domain Contrastive Learning (CDC)
광학 이미지(GT-label 할당)와 SAR 이미지(pseudo-label 할당) 사이의 유사성을 계산해 같은 클래스라면 도메인이 다르더라도 feature space에서 가깝게 뭉치게 하고, 다른 클래스라면 멀어지게 만듭니다. 즉, 광학의 지식을 SAR로 직접 전달하는 핵심 연결고리 역할을 합니다.
\[L_{CDC} = - \log \frac{\sum_{F(x_j) \in B^{i+}} e^{d(\mathrm{En}(x_i), \mathrm{En}(x_j))}}{\sum_{F(x_j) \in B^{i+}} e^{d(\mathrm{En}(x_i), \mathrm{En}(x_j))} + \sum_{F(x_j) \in B^{i-}} e^{d(\mathrm{En}(x_i), \mathrm{En}(x_j))}}\]Consistency Enhancement Learning
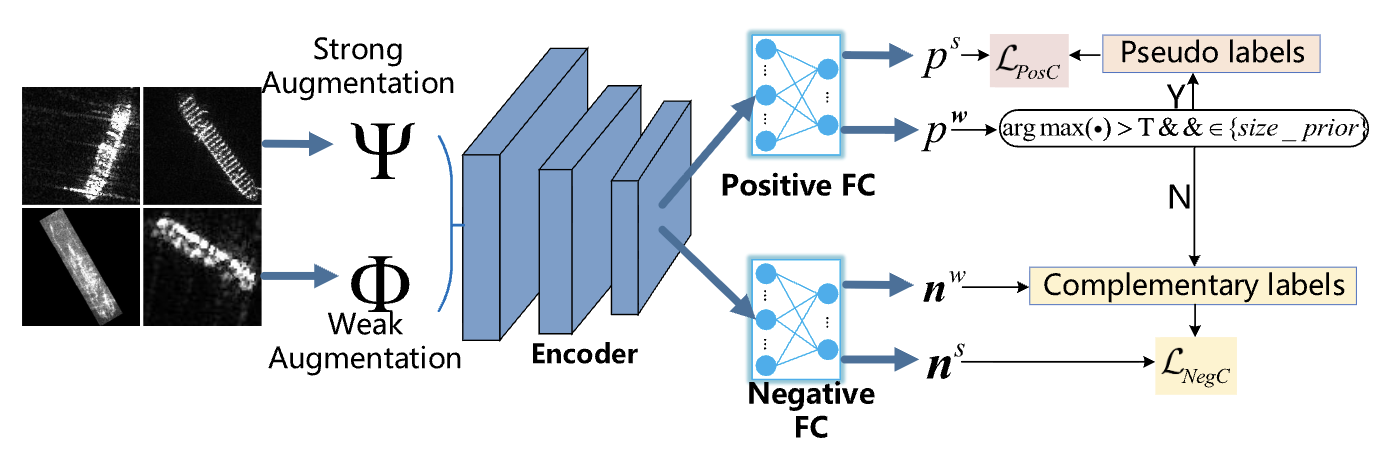
이 부분은 레이블이 없는 SAR 이미지의 클래스 구조를 스스로 정교하게 다듬는 과정입니다. 그래서 SAR 도메인에 특히 집중한 단계라고도 볼 수 있습니다. CEL의 전반적 파이프라인을 정리해보면
- 일정 임계값 이상을 넘고 prior knowledge에 부합하는 레이블을 pesudo-label로 부여합니다.
- 임계값보다 낮게 나온 라벨도 활용하는 전략을 택해, 이런 라벨들은 complementary label로 칭합니다.
- positive 분류기, negative 분류기를 따로 두어 이미지-텍스트(라벨) 쌍이 맞는지 틀린지 판단하게 합니다.
- FCDA에서처럼 원본 SAR 이미지에 weak/strong permutation을 가한 뒤, 변형을 가해도 분류기의 성능은 유지되도록 학습시킵니다.
- 연구진은 complementary label이 인코더 학습에는 적절하지 않다고 판단했기에 CEL에서는 분류기만 학습시켰습니다.
파이프라인 호흡이 좀 긴거 같습니다. 😮💨 한번 요약하고 갈게요. FECA는
- 레이블이 풍부한 광학 도메인 지식을 SAR로 전이하고 (학생 SAR이 선생 optical으로부터 기준점을 배우고)
- SAR 내부정렬을 통해 SAR 고유의 특징을 포착하는
단계로 요약할 수 있습니다!
Positive Consistency Enhancement
의사 라벨이 할당된 샘플 (신뢰도 높음 + 크기 조건 만족)
동일한 이미지에 대해 약한 증강(Weak augmentation)과 강한 증강(Strong augmentation)을 적용했을 때 Positive 분류기의 예측이 일관되도록 학습시켜, 타겟이 무엇인지(What it is)를 명확히 분류하게 합니다.
Negative Consistency Enhancement
보완 라벨이 할당된 샘플 (신뢰도 낮음 또는 크기 조건 위배)
조건을 만족하지 못하는 샘플을 단순히 버리는 대신, 타겟이 무엇이 아닌지(What it is not)를 학습하는 데 활용합니다. 할당된 보완 라벨을 사용하여 별도의 Negative 분류기를 훈련시킵니다. 이를 통해 라벨이 없는 귀중한 샘플을 버리지 않고 온전히 활용하여 SAR 도메인의 클래스 구조를 더욱 강화합니다. 이때 Negative 분류기 학습이 인코더에 부정적인 영향을 미치지 않도록 그래디언트 격리(Gradient isolation) 전략을 적용합니다.
Gradient Isolation
Negative 분류기를 학습시킬 때, 이 학습 과정에서 발생하는 오차가 역전파될 때 모델의 뼈대인 인코더의 파라미터를 업데이트하지 못하도록 차단합니다. 논문은 ‘~가 아니다’ 형식의 보완 라벨이 배들의 고유한 특징을 추출하는 인코더 학습에 악영향을 끼칠 수 있다고 보고 있습니다. 대조된 샘플 쌍으로 학습하는 DPO를 떠올려보았을 때 이런 인사이트는 상당히 의아하게 다가옵니다.
Further research
보완 라벨을 바탕으로 인코더를 업데이트시키지 못하는 현상은 DPO와 연결고리가 있음을 느꼈습니다. 업데이트하지 못한다는 문제와 간접적으로 연결되어 있는, 쌍 데이터 확보가 어렵다는 DPO의 문제를 일부 보완한 연구가 있다고 합니다.
현실적으로 “이 대답이 저 대답보다 낫다(A vs B)”라는 쌍(Pair) 데이터를 구축하는 것은 비용이 아주 많이 듭니다. 대신 SNS의 좋아요/싫어요처럼 특정 응답 하나에 대해 “이건 좋아(A다)”, “이건 별로야(A가 아니다)”라는 절대 평가(Absolute) 데이터만 쌓여있는 경우가 많죠.
최근 인공지능 학계에서는 이런 상황을 해결하기 위해 DPO 대신 KTO(Kahneman-Tversky Optimization)라는 방법론을 고안했습니다. KTO는 행동경제학의 전망 이론을 바탕으로, A와 B를 직접 짝지어 주지 않아도 ‘좋은 응답’과 ‘나쁜 응답’ 라벨만으로 모델의 선호도를 최적화할 수 있게 해줍니다.