[paper review] Olaf: Bringing an Animated Character to Life in the Physical World
Müller, et al. (2026). Olaf: Bringing an Animated Character to Life in the Physical World. Disney Research 2026. 해당 논문을 바탕으로 작성되었습니다.
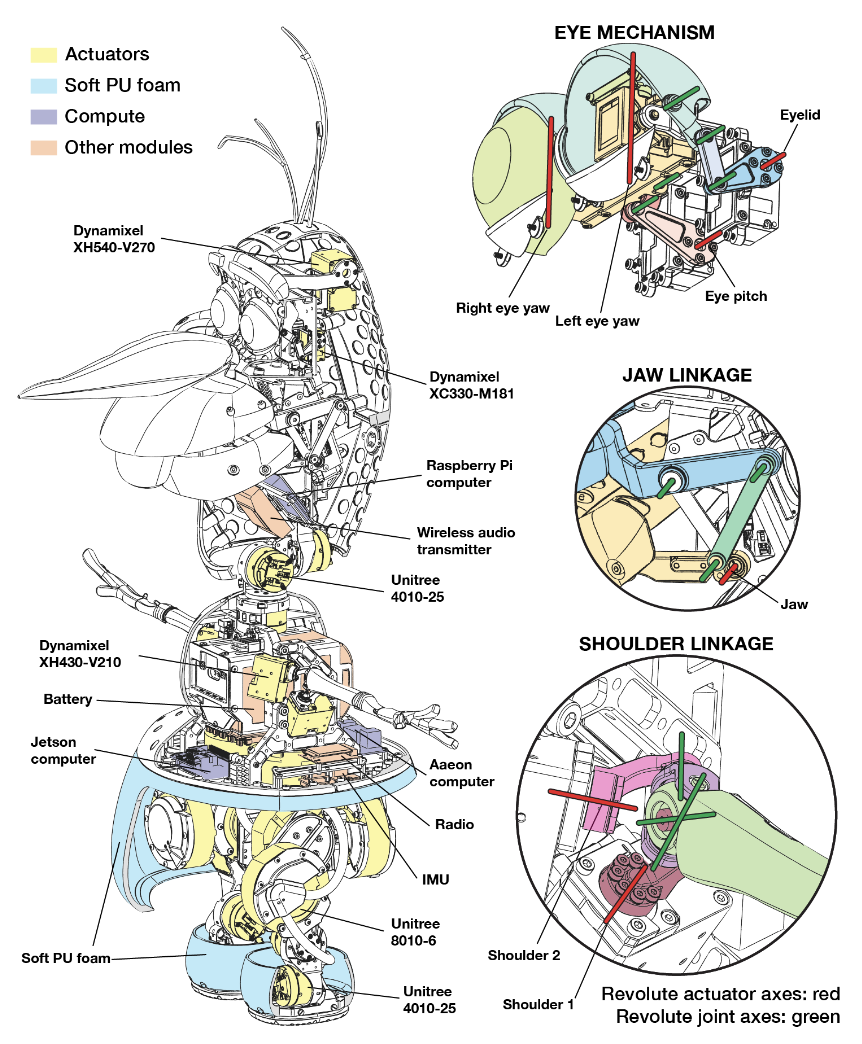
Path Frame
부드러운 이동을 위해 path frame 방법이 사용되었습니다. path frame은 쉽게 말해 로봇 몸체에게 이동해야 할 방향을 조금씩 제공하는 방법입니다. 작은 목표들을 순차적으로 제시하는 path frame은 또하 전역 좌표계(space frame)가 아닌 로봇 기준 좌표계(body frame)를 사용함으로써 더 부드러운 이동을 유도합니다.
Imitation Learning
\[\mathbf{x}_t \coloneqq \left( \mathbf{p}_t^{\mathrm{P}}, \boldsymbol{\theta}_t^{\mathrm{P}}, \mathbf{v}_t^{\mathrm{P}}, \boldsymbol{\omega}_t^{\mathrm{P}}, \mathbf{q}_t, \dot{\mathbf{q}}_t, c_t^{\mathrm{L}}, c_t^{\mathrm{R}} \right)\] \[\mathbf{g}_t \coloneqq \begin{cases} \left( \hat{\mathbf{q}}_{t}^{\mathrm{neck}}, \hat{\boldsymbol{\theta}}_{t}, \hat{\mathbf{p}}_{z,t} \right), & \text{standing} \\ \left( \hat{\mathbf{q}}_{t}^{\mathrm{neck}}, \hat{\mathbf{v}}_{t}^{\mathrm{PF}} \right), & \text{walking} \end{cases}\] \[\mathbf{x}_t = \begin{cases} f\!\left(\mathbf{p}_t^{\mathrm{PF}}, \mathbf{g}_t\right), & \text{standing} \\ f\!\left(\mathbf{p}_t^{\mathrm{PF}}, \mathbf{g}_t, \phi_t\right), & \text{walking} \end{cases}\]애니메이터들이 제작한 초기 path frame은 매핑 함수 f를 통해 물리적으로 수행 가능한 target state x로 변환됩니다. target state x는 모방학습 단계에서 정답지 역할을 하며, 모방에 대한 보상항을 구성할 때도 x를 기준으로 모방 척도를 평가하게 됩니다.
애니메이션 특유의 움직임을 재현하기 위해 로봇 제어에 있어 대규모 모션 캡처(MoCap) 데이터가 아닌, 애니메이터의 수작업 데이터를 활용한 점은 주목할만한 부분입니다.
Reinforcement Learning configuration
\[\pi(a_t \mid s_t, g_t)\] \[s_t := \left( p_t^{\mathrm{P}}, \theta_t^{\mathrm{P}}, v_t^{\mathrm{R}}, \omega_t^{\mathrm{R}}, q_t, \dot{q}_t, a_{t-1}, a_{t-2}, T_t, \phi_t \right)\]PD controller
\[\tau = K_p (q_{\text{target}} - q) + K_d (\dot{q}_{\text{target}} - \dot{q})\]Reward Formulation
\[r_t = r_t^{\text{imitation}} + r_t^{\text{regularization}} + r_t^{\text{limits}} + r_t^{\text{impact reduction}}\]
지수형 보상 (Exponential Reward)
- 몸통 수평 위치 (Torso position xy)
가중치 $k=200.0$으로 가장 높습니다. 이는 로봇의 중심 위치가 레퍼런스에서 조금만 벗어나도 엄청난 페널티를 주어, 위치 추종을 최우선으로 강제한다는 의미입니다.
CBF (Control Barrier Function)
Thermal Modeling
CBF의 해결책: CBF는 “온도가 80도를 넘으면 안 된다”는 먼 미래의 장기적인 제약 조건을, “지금 당장 온도 상승률을 이만큼 이하로 낮춰라”라는 즉각적이고 국소적인 조건으로 변환해 줍니다. 덕분에 에이전트는 먼 미래를 예측할 필요 없이 매 순간 주어지는 CBF 제약만 지키면 자연스럽게 과열을 피하는 방법을 학습할 수 있습니다.
CBF는 시스템의 상태가 안전 집합(Safe Set) 안에 머물도록 보장합니다. 시스템의 상태 $x$가 $h(x) \ge 0$을 만족하면 ‘안전하다’고 봅니다. 반대로 $h(x) = 0$은 안전 구역의 경계선입니다.
CBF의 핵심 조건: 시스템이 경계선에 다가갈 때, 경계선을 넘어가지 못하도록 상태 변화율(속도)을 제한해야 합니다.
\[\dot{h}(x, u) + \gamma h(x) \ge 0\]경계선($h(x)=0$)에 가까워질수록, 경계선을 향해 돌진하는 속도($\dot{h}$)를 강제로 줄여라~
\[h(T) = T_{max} - T \ge 0\] \[-\dot{T} + \gamma (T_{max} - T) \ge 0\] \[\dot{T} \le \gamma (T_{max} - T)\] \[\dot{T} = -\alpha (T - T_{\text{ambient}}) + \beta \tau^2\]