[paper review] Latent Action Pretraining from Videos (ICLR 2025)
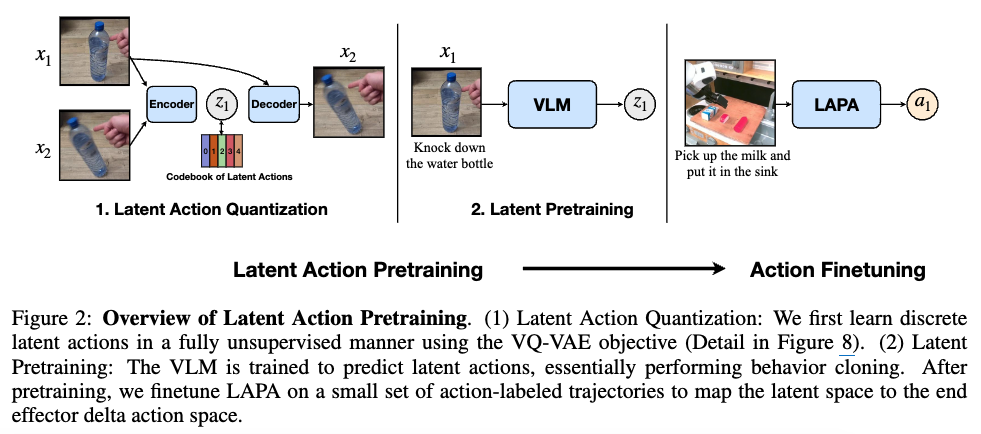
Latent Action Pretraining
Latent Action Quantization
Latent Actions이란 첫 번째 단계인 ‘Latent Action Quantization’을 통해 정의된 이산적인 토큰입니다. 이는 로봇의 관절 각도 같은 물리적 수치가 아니라, 비디오의 시각적 변화(비디오 프레임 간 차이인 delta)를 대표하는 심볼이라고 할 수 있습니다. EgoBridge에서도 EgoVLA와 달리 정형화된 표현공간인 MANO 모델이 아닌 고차원 잠재공간에서 로봇-인간 feature alignment를 수행했었죠. 고차원 공간의 유연함이 갖는 강점을 여기서도 세삼 느끼게 됩니다! 이어서 Latent Action Pretraining의 학습 목표는 현재 이미지 xt와 언어 지시문이 주어졌을 때, 다음 상태로 넘어가기 위해 필요한 잠재 행동 zt를 예측하는 것입니다.
구성요소
- Encoder(Inverse Dynamics Model 역할) : 두 개의 연속된 이미지 프레임(xt, xt+H)을 입력받아 그 사이의 변화를 나타내는 Latent Action(zt)을 추출합니다.
- IDM과 반대로 Forward Dynamics Model은 특정 액션을 취했을 때 상태가 어떻게 변화할까?에 초점을 둡니다.
- Decoder(World Model 역할) : 현재 상태(xt)와 Latent Action(zt)을 입력받아 다음 상태(xt+H)를 시각적으로 생성, 이로써 물리적인 로봇 하드웨어 없이도 신경망 내에서 가상으로 로봇을 움직여보는 Closed-loop Rollout이 가능해집니다.
Policy Model(특정 상태에서 어떤 액션을 취할지 결정)과 World Model(특정 액션을 취했을 때 상태가 어떻게 변화할지 예측)을 결합한 형태라는 점에서 기존 연구와 차별점
Latent Pretraining
비디오와 텍스트를 받아 VLM이 앞서 학습된 Encoder를 모방 학습하는 단계입니다. 보통 모방 학습은 전문가(여기서는 사전학습된 인코더)의 실제 행동을 그대로 따라 하도록 학습하는 방식입니다. LAPA에서는 이를 확장하여 실제 액션 대신 잠재 액션을 모방하는데, 인터넷 비디오 같이 로봇 제어 값이 없는 상황에서는 VQ-VAE가 생성한 잠재 토큰을 정답 행동으로 간주하고, VLM이 이를 맞추도록 학습하게 합니다.
\[\mathcal{L} = \sum \log P_\theta(z_t | x_t, \text{Instruction})\]주요 이점
실제 로봇을 조종해서 얻은 Teleoperation 데이터는 수집이 매우 비싸지만, 유튜브 같은 일반 비디오 사용을 용이하게 해 확장성이 높아집니다. 또한 물리적 수치를 배우기 전에 “컵을 집으려면 손을 컵 쪽으로 뻗어야 한다”는 상위 수준의 전략을 먼저 익히게 됩니다. 그리고 이 논문에서는 OpenVLA와 같은 최신 모델보다 사전 학습 효율을 30배 이상 높이면서도 더 좋은 성능을 냈다고 밝히고 있습니다.
LAPA를 기존의 Video PreTraining와 비교하자면, VPT는 별도의 Inverse Dynamics Model을 써서 Pseudo-action 레이블을 만들지만, LAPA는 VQ-VAE를 통해 데이터 자체에서 잠재적인 행동 단위를 스스로 찾아낸다는 점에서 일반화 능력이 극대화됩니다. 즉, 로봇의 관절 각도나 집게의 좌표 같은 특정 로봇 하드웨어에 종속된 prior 정보를 미리 정의할 필요가 없습니다.
Action Finetuning
아쉽게도 .. 이 논문도 라벨링으로부터, 로봇데이터로부터 완전히 자유롭지는 않습니다. 사전에 정의한 잠재 액션이 실제 로봇의 end-effector와 동치는 아니기 때문에 라벨링이 포함된 소규모 로봇 데이터로 미세조정하는 단계가 필요합니다.
Equi-depth Binning 샘플링
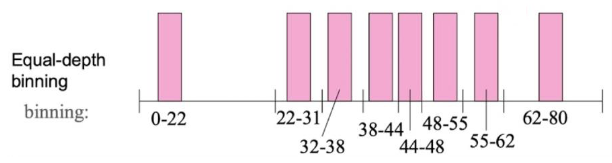 실제 로봇 데이터를 샘플링하는데 있어 OpenVLA 논문을 참고했다고 하며, 데이터 편향 완화를 위해 data equal allocation 기법이 사용되었습니다. 전체 로봇 제어 정보를 동일한 규모를 갖도록 여러 구간들로 쪼개고, 마치 VQ-VAE처럼 VLM이 예측 구간을 맞추는 분류 문제로 재정의하였습니다. Binning을 하는 이유는 정확한 제어 수치를 그대로 예측하게 하는 것보다, 전체 데이터 분포를 기준으로 균등하게 나눈 구간 중 하나를 고르게 하는 것이 모델 입장에서는 훨씬 배우기 쉽고 정확하기 때문입니다.
실제 로봇 데이터를 샘플링하는데 있어 OpenVLA 논문을 참고했다고 하며, 데이터 편향 완화를 위해 data equal allocation 기법이 사용되었습니다. 전체 로봇 제어 정보를 동일한 규모를 갖도록 여러 구간들로 쪼개고, 마치 VQ-VAE처럼 VLM이 예측 구간을 맞추는 분류 문제로 재정의하였습니다. Binning을 하는 이유는 정확한 제어 수치를 그대로 예측하게 하는 것보다, 전체 데이터 분포를 기준으로 균등하게 나눈 구간 중 하나를 고르게 하는 것이 모델 입장에서는 훨씬 배우기 쉽고 정확하기 때문입니다.
이후 기존의 Latent Action Head(MLP 층)를 무시하고 새로운 Action Head를 붙인 뒤, 실제 로봇 액션인 Discretized Robot Action(Bin Index)을 출력하도록 미세조정합니다.
visual encoder와 language model을 바라보는 차이
latent pretraining, action finetuning 단계 모두 visual encoder는 고정한채 language model만 full-fintuning하는 미세조정 전략을 취했습니다.
이유를 짐작하건데 로봇 데이터(Bridgev2)는 인터넷 규모의 데이터에 비해 양이 매우 적습니다. 만약 Encoder까지 튜닝하면, 기존에 갖고 있던 풍부한 시각 지식을 잃어버리고(Catastrophic Forgetting) 특정 로봇 환경의 좁은 데이터에만 과적합될 위험이 큽니다.
Action as a Language : LLM은 수많은 텍스트를 통해 ‘다음에 올 토큰을 예측하는 능력’이 극대화되어 있습니다. LLM을 미세조정하는 것은 이 강력한 ‘다음 토큰 예측 엔진’을 ‘물리적 법칙을 따르는 액션 시퀀스 생성 엔진’으로 개조하는 과정입니다.
visual encoder는 무엇이 보이는지만 말해줄 뿐이고, Projector는 데이터를 단순 전달할 뿐입니다. 결국 “그래서 지금 무엇을 해야 하는가”라는 최종 판단은 LLM의 몫입니다. LLM은 Hierarchical Planning에 강하며, 즉 사용자로부터 받은 지시문을 분해하고 시각 정보를 바탕으로 다음 토큰을 생성하는 결정 작업에 특화되어 있습니다.