[PyTorch 벗기기] pytorch for clip loss, multi_head_attention_forward(), torch.nn.modules.Linear
Pytorch for CLIP Loss
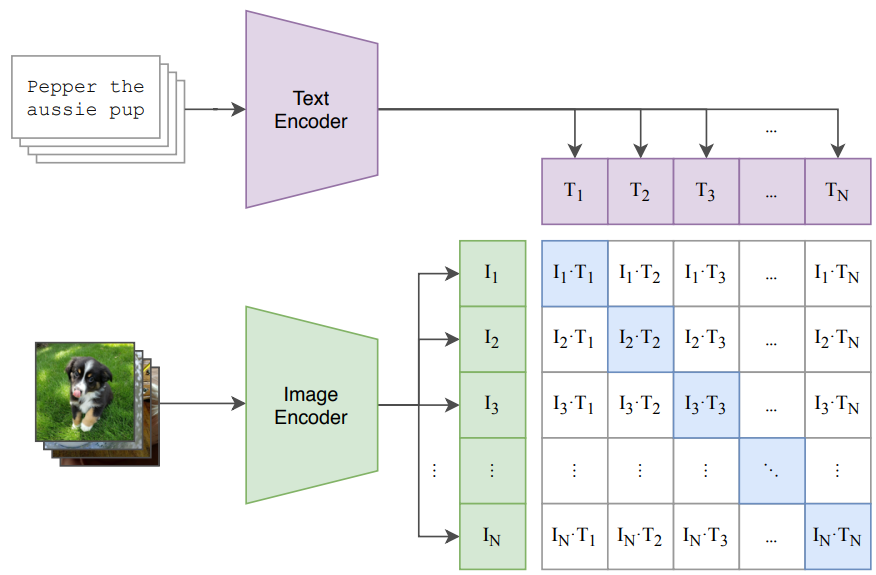
[github] src/open_clip/loss.py
Gradient trick
# We gather tensors from all gpus
if gather_with_grad:
all_image_features = torch.cat(torch.distributed.nn.all_gather(image_features), dim=0)
all_text_features = torch.cat(torch.distributed.nn.all_gather(text_features), dim=0)
else:
gathered_image_features = [torch.zeros_like(image_features) for _ in range(world_size)]
gathered_text_features = [torch.zeros_like(text_features) for _ in range(world_size)]
dist.all_gather(gathered_image_features, image_features)
dist.all_gather(gathered_text_features, text_features)
if not local_loss:
# ensure grads for local rank when all_* features don't have a gradient
gathered_image_features[rank] = image_features
gathered_text_features[rank] = text_features
all_image_features = torch.cat(gathered_image_features, dim=0)
all_text_features = torch.cat(gathered_text_features, dim=0)
def get_logits(self, image_features, text_features, logit_scale):
if self.world_size > 1:
all_image_features, all_text_features = gather_features(
image_features, text_features,
self.local_loss, self.gather_with_grad, self.rank, self.world_size, self.use_horovod)
def forward(self, image_features, text_features, logit_scale, output_dict=False):
device = image_features.device
logits_per_image, logits_per_text = self.get_logits(image_features, text_features, logit_scale)
labels = self.get_ground_truth(device, logits_per_image.shape[0])
total_loss = (
F.cross_entropy(logits_per_image, labels) +
F.cross_entropy(logits_per_text, labels)
) / 2
return {"contrastive_loss": total_loss} if output_dict else total_loss
multi_head_attention_forward()
[github] multi_head_attention_forward()
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + \text{mask}\right)V\]def multi_head_attention_forward(
query: Tensor, key: Tensor, value: Tensor,
embed_dim_to_check: int, num_heads: int,
in_proj_weight: Optional[Tensor],
in_proj_bias: Optional[Tensor],
bias_k: Optional[Tensor],
bias_v: Optional[Tensor],
add_zero_attn: bool,
dropout_p: float,
out_proj_weight: Tensor,
out_proj_bias: Optional[Tensor],
training: bool = True,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
use_separate_proj_weight: bool = False,
q_proj_weight: Optional[Tensor] = None,
k_proj_weight: Optional[Tensor] = None,
v_proj_weight: Optional[Tensor] = None,
static_k: Optional[Tensor] = None,
static_v: Optional[Tensor] = None,
average_attn_weights: bool = True,
is_causal: bool = False,
) -> tuple[Tensor, Optional[Tensor]]:
tens_ops = (query, key, value, in_proj_weight, in_proj_bias,
bias_k, bias_v, out_proj_weight, out_proj_bias)
if has_torch_function(tens_ops):
return handle_torch_function(...)
is_batched = _mha_shape_check(query, key, value,
key_padding_mask, attn_mask, num_heads)
# 입력이 (L, E) 같은 unbatched면 (L, 1, E)로 바꿔서
# 내부는 항상 (L, N, E) 형태로 계산하게 통일
if not is_batched:
query = query.unsqueeze(1)
key = key.unsqueeze(1)
value = value.unsqueeze(1)
if key_padding_mask is not None:
# key_padding_mask도 batch 차원 추가
key_padding_mask = key_padding_mask.unsqueeze(0)
입력이 unbatched여도, 내부 처리 코드는 항상 ‘배치가 있다’는 전제로 깔끔하게 돌리기 위해서, 배치=1 차원을 강제로 추가하는 단계
# --- 1단계: Input Projection (Q, K, V 생성) ---
if not use_separate_proj_weight:
# 하나의 행렬(in_proj_weight)에 Q, K, V 가중치가 합쳐져 있는 경우(보통 self-attn)
# 나중에 fastpath
if in_proj_weight is None:
raise AssertionError("use_separate_proj_weight is False but in_proj_weight is None")
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
else:
# Q, K, V 각각 별도의 가중치 행렬을 사용하는 경우
# use_seperate_proj_weight가 True일 때 별도 처리 없이 K, V를 인코더에서 가져올 수 있게 됨(cross-entropy)
if q_proj_weight is None or k_proj_weight is None or v_proj_weight is None:
raise AssertionError("use_separate_proj_weight is True but projection weights are missing")
if in_proj_bias is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = in_proj_bias.chunk(3)
q, k, v = _in_projection(
query, key, value,
q_proj_weight, k_proj_weight, v_proj_weight,
b_q, b_k, b_v,
)
트랜스포머는 내부적으로 Q,K,V에게 서로 다른 역할을 부여하고, 각 head마다 또 다른 표현을 학습 그리고 계산량과 차원을 조절하기 위해 input에 대해 projection을 수행한다. 그리고 PyTorch는 성능 때문에 이 세 개(Q,K,V)를 하나의 큰 weight에 붙여서 처리한다. 그 다음 _in_projection_packed에서 in_proj_weight.T + in_proj_bias를 한 번만 수행할 수 있다. 이렇게 하면 matmul 호출이 3번에서 1번으로 줄게 되어 속도 면에서 이득이다.
key padding mask + atten mask
# --- 6단계: Mask 통합 (Padding Mask + Attention Mask) ---
if key_padding_mask is not None:
...
key_padding_mask = (
key_padding_mask.view(bsz, 1, 1, src_len)
.expand(-1, num_heads, -1, -1)
.reshape(bsz * num_heads, 1, src_len)
)
if attn_mask is None:
attn_mask = key_padding_mask
else:
attn_mask = attn_mask + key_padding_mask
key_padding_mask
- 배치 안에서 실제 토큰 vs 패딩 토큰을 구분하는 이진 마스크
- “hello [PAD] [PAD]” / “how are you” 두 문장을 하나의 배치로 만들려면 뒷부분을 [PAD]로 채워야 하는데, attention이 이 패딩 위치까지 참고하면 쓸데없는 정보를 학습하는 걸 방지한다.
attn_mask
- 구조적인 제약(미래 보기 금지 등)에 관여하는 마스크
- 자기보다 미래에 있는 토큰을 보면 안 되는 언어모델/decoder에서 사용
Scaled Dot-Product Attention : 수학적 경로 (need_weights=True)
# 학습이 아니면 dropout 비활성화
if not training:
dropout_p = 0.0
# --- 5단계: 실제 어텐션 계산 (수학 버전) ---
if need_weights:
# q: (batch * heads, tgt_len, head_dim)
_B, _Nt, E = q.shape
# Scaled Dot-Product의 scale = 1 / sqrt(d_k)
q_scaled = q * math.sqrt(1.0 / float(E))
if is_causal and attn_mask is None:
# causal인데 마스크가 없다면 아직 구현 안 됨 (PyTorch FIXME)
raise AssertionError("FIXME: is_causal not implemented for need_weights")
if attn_mask is not None:
# attn_output_weights = attn_mask + (q_scaled @ k^T)
# (baddbmm: batch matrix add + matmul 한 번에)
attn_output_weights = torch.baddbmm(
attn_mask,
q_scaled,
k.transpose(-2, -1),
)
else:
# 기본 QK^T / sqrt(d_k)
attn_output_weights = torch.bmm(
q_scaled,
k.transpose(-2, -1),
)
# 마지막 차원(src_len)에 대해 softmax → 각 query 위치에서 src 토큰들에 대한 분포
attn_output_weights = softmax(attn_output_weights, dim=-1)
if dropout_p > 0.0:
# attention weight에 dropout 적용 (학습 시 regularization)
attn_output_weights = dropout(
attn_output_weights,
p=dropout_p,
)
# V와 곱해서 최종 context vector 계산
# (batch * heads, tgt_len, head_dim)
attn_output = torch.bmm(attn_output_weights, v)
# (batch * heads, tgt_len, head_dim)
# → (tgt_len, batch, embed_dim)로 다시 합치기
attn_output = (
attn_output
.transpose(0, 1) # (tgt_len, batch*heads, head_dim)
.contiguous()
.view(tgt_len * bsz, embed_dim) # (tgt_len*batch, embed_dim)
)
# 마지막 Linear (out_proj): 모든 헤드를 다시 projection해서
# residual 연결 전에 쓸 수 있는 형태로 맞춤
attn_output = linear(
attn_output,
out_proj_weight,
out_proj_bias,
)
attn_output = attn_output.view(
tgt_len,
bsz,
attn_output.size(1),
)
# 가중치 텐서도 (batch, heads, tgt_len, src_len)로 reshape
attn_output_weights = attn_output_weights.view(
bsz, num_heads, tgt_len, src_len
)
if average_attn_weights:
# 모든 헤드의 attention map을 평균낼지 여부
attn_output_weights = attn_output_weights.mean(dim=1)
# 입력이 unbatched였으면 다시 배치 차원 제거
if not is_batched:
attn_output = attn_output.squeeze(1)
attn_output_weights = attn_output_weights.squeeze(0)
return attn_output, attn_output_weights
Scaled Dot-Product Attention : 빠른(최적화된) 경로 (need_weights=False)
else:
# --- 6단계: 최적화된 C++/CUDA SDPA 커널 호출 (가중치 반환 X) ---
if attn_mask is not None:
if attn_mask.size(0) == 1 and attn_mask.dim() == 3:
# (1, tgt_len, src_len): 모든 배치/헤드가 같은 마스크 사용
attn_mask = attn_mask.unsqueeze(0) # (1, 1, tgt_len, src_len) 느낌
else:
# 각 헤드마다 다른 마스크: (batch * heads, 1, src_len) 등에서
# (batch, heads, tgt_len, src_len) 꼴로 reshape
attn_mask = attn_mask.view(
bsz, num_heads, -1, src_len
)
# q,k,v를 (batch, heads, L, head_dim)로 바꿔서 SDPA에 넘김
q = q.view(bsz, num_heads, tgt_len, head_dim)
k = k.view(bsz, num_heads, src_len, head_dim)
v = v.view(bsz, num_heads, src_len, head_dim)
# 여기서부터는 C++/CUDA 백엔드(FlashAttention, cuDNN 등)가
# softmax, dropout까지 한 번에 처리해 줌
attn_output = scaled_dot_product_attention(
q, k, v,
attn_mask,
dropout_p,
is_causal,
)
# (batch, heads, tgt_len, head_dim) → (tgt_len, batch, embed_dim)
attn_output = (
attn_output
.permute(2, 0, 1, 3) # (tgt_len, batch, heads, head_dim)
.contiguous()
.view(bsz * tgt_len, embed_dim)
)
attn_output = linear(
attn_output,
out_proj_weight,
out_proj_bias,
)
attn_output = attn_output.view(
tgt_len,
bsz,
attn_output.size(1),
)
if not is_batched:
attn_output = attn_output.squeeze(1)
# need_weights=False 이라 attention map은 반환하지 않음
return attn_output, None
C++ Math 백엔드 핵심 SDPA 구현
// aten/src/ATen/native/transformers/attention.cpp 中 일부
at::Tensor _scaled_dot_product_attention_math(
const at::Tensor& query, // (B, H, L_q, D)
const at::Tensor& key, // (B, H, L_k, D)
const at::Tensor& value, // (B, H, L_k, D)
...
) {
// 1) QK^T: 각 쿼리가 각 키와 얼마나 비슷한지(유사도)를 계산
at::Tensor attn_weight =
at::matmul(query, key.transpose(-2, -1)); // (B, H, L_q, L_k)
// 2) scale factor: 1 / sqrt(D)로 나눠서 값이 너무 커지는 것 방지
attn_weight = attn_weight * scale_factor;
// 3) 마스크가 있으면 여기서 더해 줌 (패딩, causal 등)
if (attn_mask.defined()) {
attn_weight = attn_weight.add(attn_mask);
}
// 4) 마지막 차원(L_k)에 대해 softmax → 확률 분포로 변환
attn_weight = at::_softmax(attn_weight, -1);
// 5) 학습 중이면 dropout 적용
if (dropout_p > 0.0) {
attn_weight = at::dropout(attn_weight, dropout_p, train);
}
// 6) Value와 곱해서 최종 출력 (context vector) 계산
return at::matmul(attn_weight, value); // (B, H, L_q, D)
}