Parameter-Efficient Fine-Tuning (PEFT)
LoRA(Low-Rank Adaptation of Large Language Models) 구현 및 이해
주요 PEFT 방법론 두 가지
① Re-parameterization (재매개변수화) - LoRA
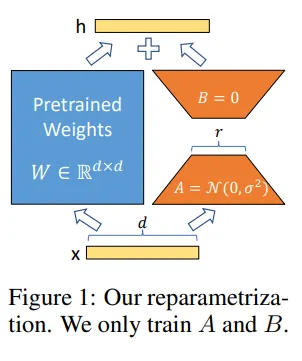
현재 가장 널리 쓰이는 방식인 LoRA (Low-Rank Adaptation)가 대표적입니다. 가중치의 업데이트량($\Delta W$)을 직접 학습하는 대신, 두 개의 작은 저차원 행렬($A, B$)로 분해하여 학습합니다.
원리: 고정된 원래 가중치 $W$에 대해 $W + \Delta W = W + BA$로 정의하며, 여기서 $A$와 $B$만 학습합니다.
수식: $W \in \mathbb{R}^{d \times k}, B \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k}$ (이때 $r \ll d, k$)
② Additive (추가형) - Adapters & Prompt Tuning기존 모델의 구조는 그대로 두고, 새로운 레이어나 벡터를 추가하여 해당 부분만 학습합니다.
Adapters: Transformer 블록 내부에 작은 Bottleneck 레이어(Adapter)를 삽입합니다.
Prompt/Prefix Tuning: 입력 데이터 앞에 학습 가능한 ‘가상 토큰(Soft Prompt)’을 붙여 모델의 출력을 제어합니다.
LoRA
LoRA는, 잔차 학습(residual learning)의 형태로 작동하며, 새로운 도메인의 gradient를 기존 weight(W0)에 추가적인 보정 항으로 분배하여 효율적으로 적응한다.
추가적으로, Bottleneck 구조에서 BA의 값이 커지므로, 이 값을 bottleneck 크기로 나누어 정규화하는 기법도 함께 적용된다.
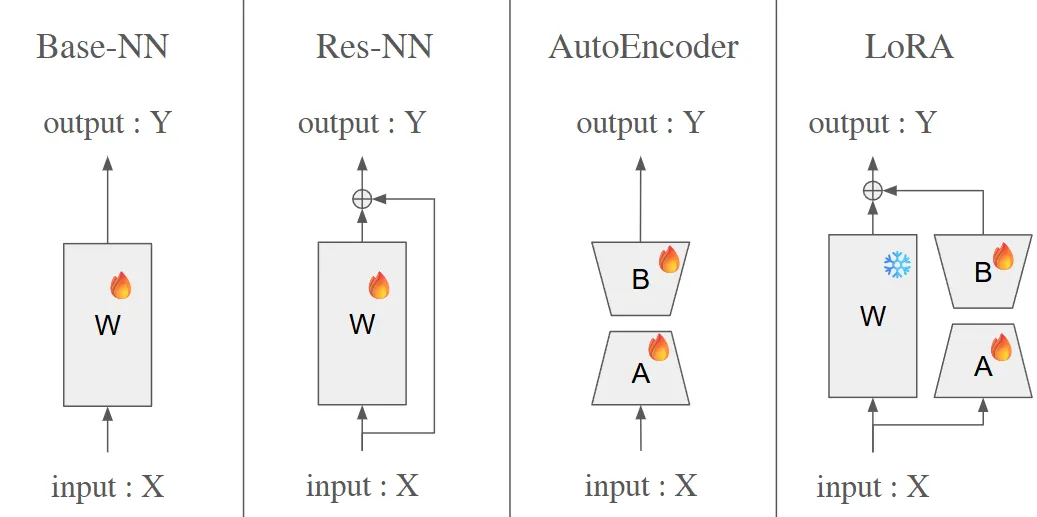
LoRA 구조는 일종의 병목(bottleneck) 형태로 동작하며, 정보의 핵심 표현만을 압축·복원하는 방식으로 효율적인 적응을 가능하게 한다.
“병목(bottleneck) 형태로 동작한다”는 말은, LoRA가 중간에 인위적으로 차원을 확 줄였다가 다시 키우는 좁은 통로를 하나 더 만들어서 모델이 “정말 필요한 변화(핵심 표현)”만 이 통로에 담도록 강제하는 효과가 있다. 부가적인 이점으로 학습해야할 파라미터 수가 크게 줄고 표현의 요동침(편차)을 줄여 학습 안정성을 높인다는 점이 있다.
LoRA가 잔차 네트워크 형태를 띄는 이유
학습 안정성과 Catastrophic Forgetting 완화 : 초기에는 B=0, A는 작은 분산으로 초기화해서 ΔW≈0이므로, 학습 초반에는 거의 W₀와 같은 동작을 합니다. 이후 그라디언트가 ΔW에만 쌓이므로, 기존 표현 공간을 크게 뒤틀지 않고 “잔차적으로” 새로운 도메인 정보를 얹는 형태가 되어 파괴적 망각을 줄입니다.
도메인별·태스크별 “추가층”처럼 다루기 쉬움 : ΔW를 잔차로 더하는 구조라서, 여러 도메인용 LoRA(ΔW₁, ΔW₂ …)를 같은 W₀ 위에 얹었다 뗐다 할 수 있습니다. 마치 공용 백본 + 태스크별 작은 헤드처럼 관리가 가능해집니다.
LoRA의 한계
입력에 따라 서로 다른 LoRA 모듈을 선택적으로 활성화하는 MoE(Mixture of Experts) 구조와 LoRA를 결합한 MoL(Mixture of LoRA) 방식의 등장