Stable Diffusion
Stable Diffusion
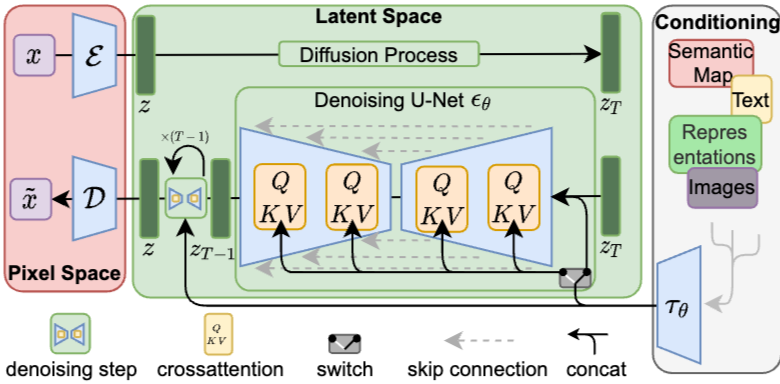 source : https://arxiv.org/abs/2112.10752
source : https://arxiv.org/abs/2112.10752
$T-1$의 의미: 총 $T$ 단계의 스텝 중 마지막 단계에 도달하기 전까지 U-Net을 계속 통과시키며 데이터를 업데이트함, $T$번의 단계를 거치며 아주 미세한 노이즈부터 큰 형태까지 단계적으로 잡아나갈 수 있게 되어 Stable Diffusion은 기존 VAE나 GAN보다 더 정교한 이미지 생성이 가능함
stable diffusion은 VAE를 기반으로 한 생성모델이며 VAE의 인코더와 동일하게 인코더 출력 $z$는 인코더가 예측한 잠재 공간의 모멘트$(\mu, \sigma)$다.
Denoising U-Net 역시 z_t에서 $z_{t-1}$로 갈 때, 이전 단계의 평균과 분산을 예측하는 방식으로 동작함, 하지만 이는 노이즈를 얼마나 제거할 것인가에 대한 분포일 뿐, 처음에 VAE 인코더가 이미지를 압축하며 만든 이미지의 특징 분포$(\mu, \sigma)$와는 다른 개념
Conditioning
텍스트, Semantic Map, 다른 이미지 등의 다양한 입력을 받아 모델이 원하는 결과를 출력하도록 유도한다. 또한 이미지 생성 조건에 따라 정보를 주입하는 방식이 다르다(Switch 부분). 공간적인 정보가 중요한 경우(Semantic Map 등)는 Concatenation 방식을 사용하고, 텍스트와 같이 보다 추상적인 정보는 Cross-Attention을 통해 주입한다.
\[Attention(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right) \cdot VAttention(Q,K,V)=softmax(dQKT)⋅V\]CompVis와 Stability AI가 모델을 실무적으로 배포한 이후에는, OpenAI의 CLIP(ViT-L/14) 텍스트 인코더를 고정된 $\tau_\theta$로 사용하는 방식이 표준이 되었다.
인코더와 디퓨전 모듈을 분리한 이유
이미지 인코딩과 디퓨전 과정을 분리한 이유는 인코딩와 디퓨전의 역할이 다르기 때문이다.
- VAE 인코더의 목적 (Data Compression): 수많은 픽셀 데이터 중에서 핵심적인 저차원 정보(특징)만 남기고 나머지는 버리는 것이다.
- Diffusion의 목적 (Generative Modeling): 아무것도 없는 無의 상태(노이즈)에서 어떻게 하면 有의 상태를 만들어낼지를 학습한다.
만약 인코더 하나에서 데이터 요약과 새로운 데이터 생성 두 가지 역할을 모두 수행하게 되면 복잡도가 증가하게 된다. 또한 인코딩과 디퓨전의 분리는 목적에 맞는 제어를 더 용이하게 한다. 예를 들어 생성모델은 보통 추론 단계에서 이미지 입력 없이, 즉 별도의 인코딩 과정 없이 무작위 가우시안 노이즈 한 덩이를 U-Net에 넣는다. 이때 인코더와 디퓨전 모듈이 분리되어 있다면 샘플링 단계부터 바로 진행할 수 있게 된다.
픽셀이 아닌 $z$에 노이즈를 더하는 이유 (Latent Diffusion)
잠재 공간은 픽셀 공간보다 차원 수가 낮아서 가볍고, 훨씬 적은 연산량으로 유사한 효과를 낼 수 있다.
U-Net
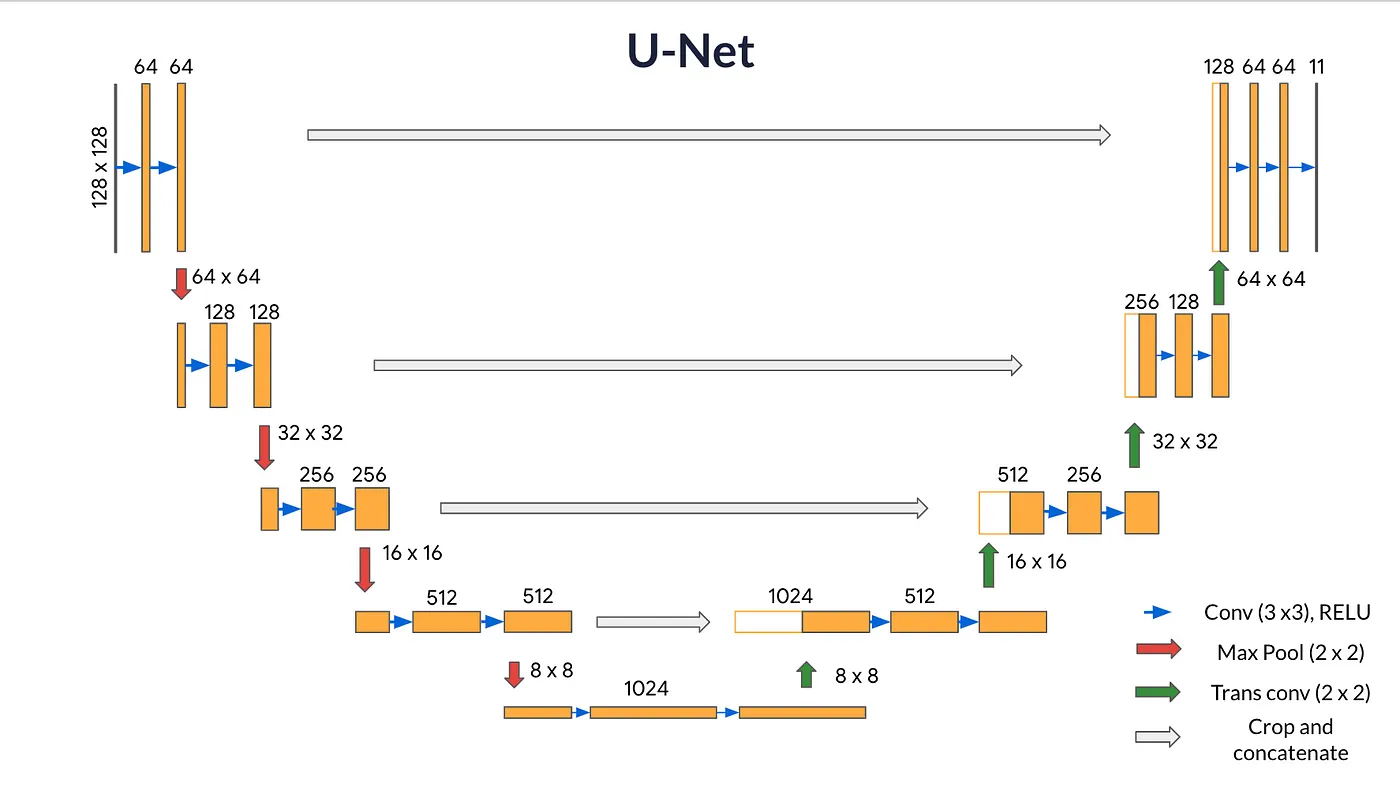 source : https://ankittaxak5713.medium.com/stable-diffusion-models-24a953276240
source : https://ankittaxak5713.medium.com/stable-diffusion-models-24a953276240