[paper review] Attention is all you need
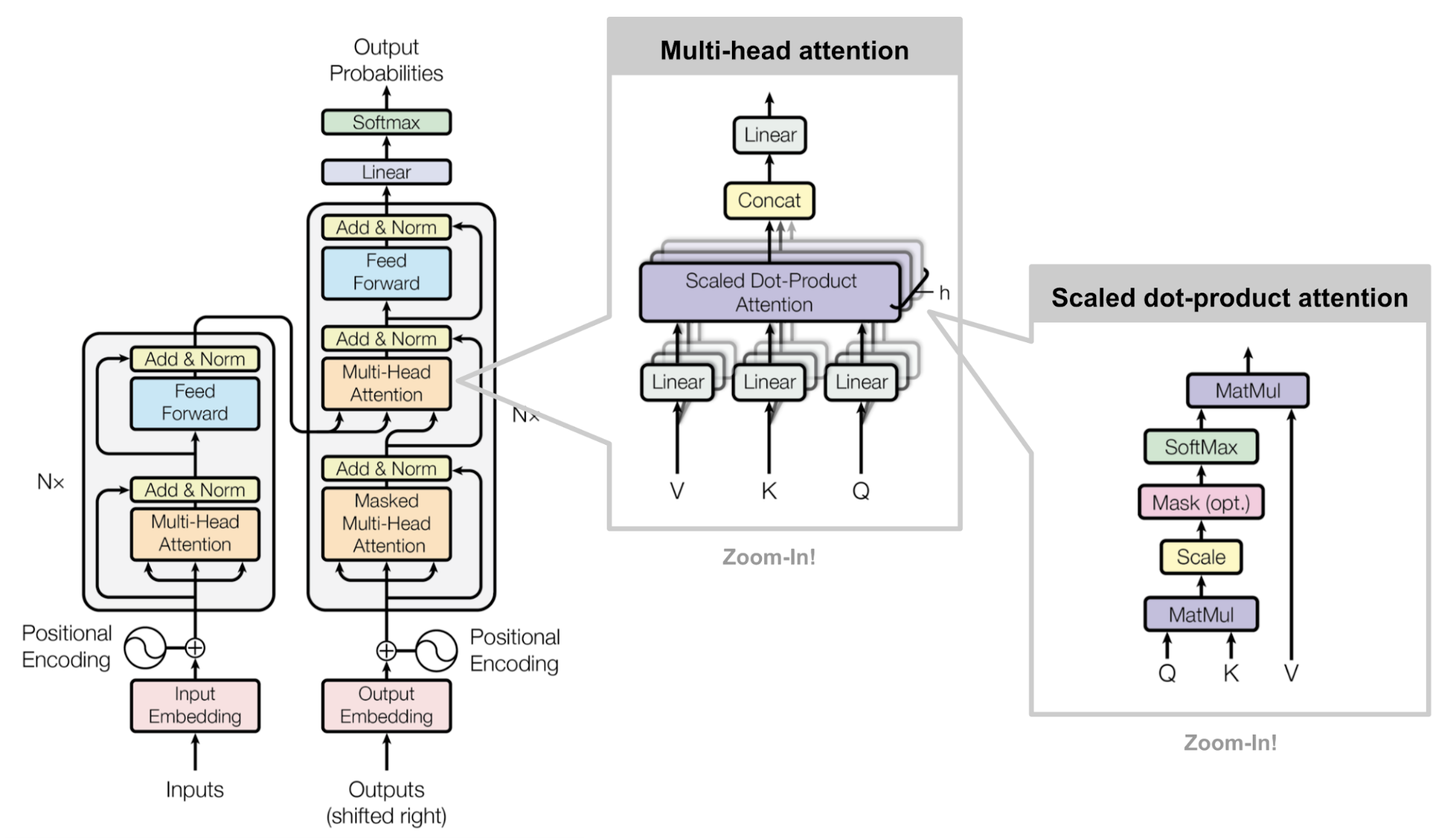
Scaled Dot-Product Attention and why
additive attention and dot-product (multiplicative) attention
Multi-Head Attention and why
🛠️ Writing in progress 🛠️
Positional Encoding and why
\[PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right)\] \[PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)\]- $i$ : 하나의 단어를 $d_{model}$ 차원의 벡터로 표현할 때, 이 벡터 내부의 몇 번째 칸인지를 나타내는 지표
- 문장의 길이를 $L$, 임베딩 차원을 $d$라고 할 때, 위치 인코딩 행렬은 $(L \times d)$ 크기를 가짐
주목할 부분은 차원 인덱스의 offset에 대해 삼각함수가 다른 삼각함수의 선형결합으로 표현될 수 있다는 것입니다. 단순 선형 덧셈으로 서로 다른 위치의 위치 정보를 계산할 수 있다는 건 기계에게 positional learning을 용이하게 하는 셈입니다.
규제의 일종으로도 느껴지는 삼각함수 자체의 성질을 보고 어텐션의 본질적인 기능? 중 하나가 떠올랐습니다. 밑에서 더 자세하게 서술하겠지만 어텐션은 멀리 떨어진 단어끼리도 어텐션 맵만 있으면 그들간 관계 파악을 용이하게 해줍니다. 이는 마치 교통체증을 줄이고 행복도를 높이고자 한 도시의 다리 설계에 관여하는 모습 같기도 합니다. 참고로 저는 셜록현준으로 유명하신 유현준 교수님의 광팬이기도 한지라, 건축을 비유의 대상으로 자주 삼습니다!