Bi-Directional Attention
BDA: Bi-directional attention for zero-shot learning
위 논문을 참고하여 작성하였습니다.
본 논문에서는
BDA의 이점
비전 특징 ↔ 시맨틱 속성(텍스트/attribute) 사이를 양방향으로 어텐션시켜서, 두 공간을 서로 조건부로 보게 만든다. 그 결과, seen 클래스에서 학습된 visual–semantic 관계를 더 정교하게 정렬하게 만들어 unseen으로 넘어갈 때 domain shift를 줄어들게 된다.
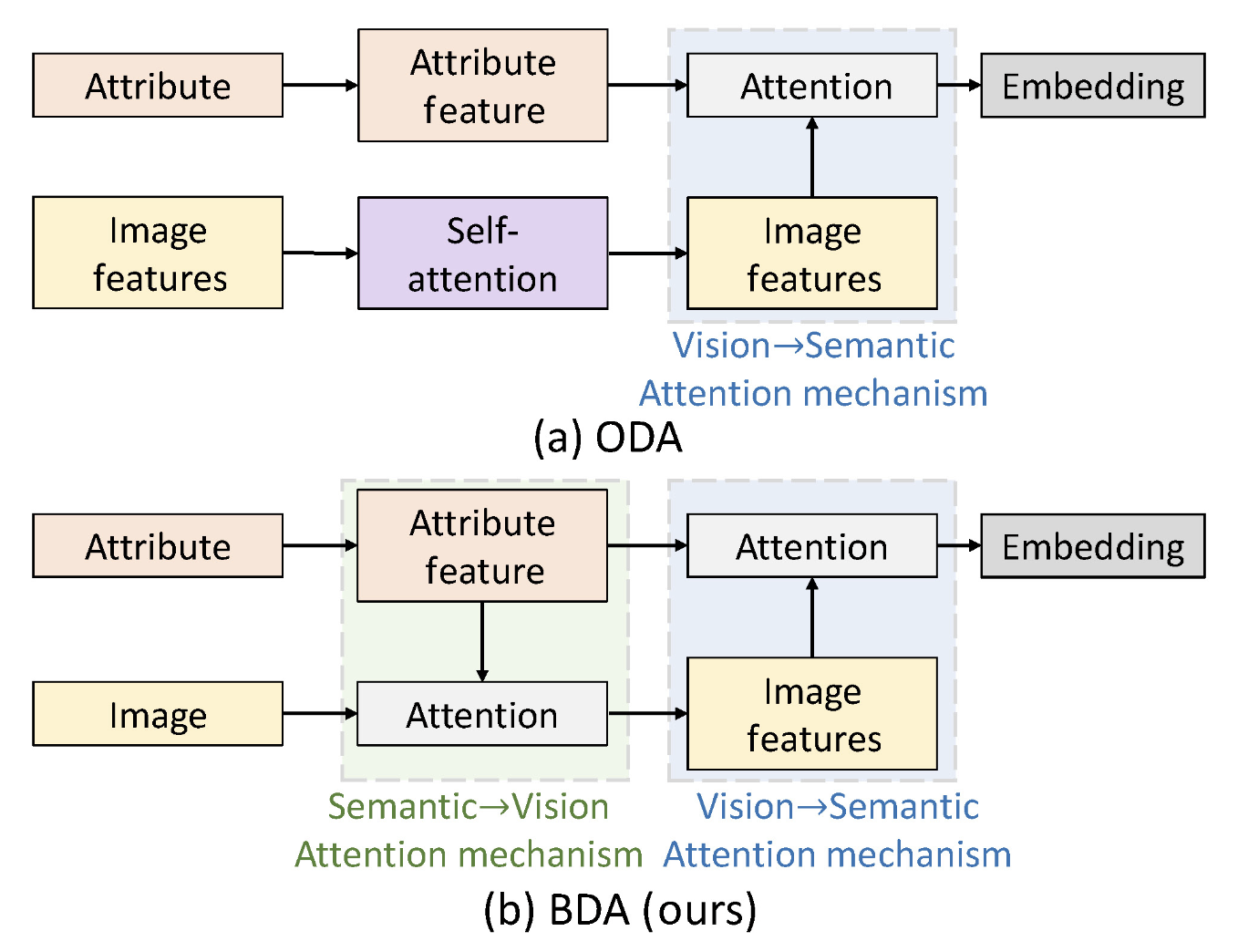
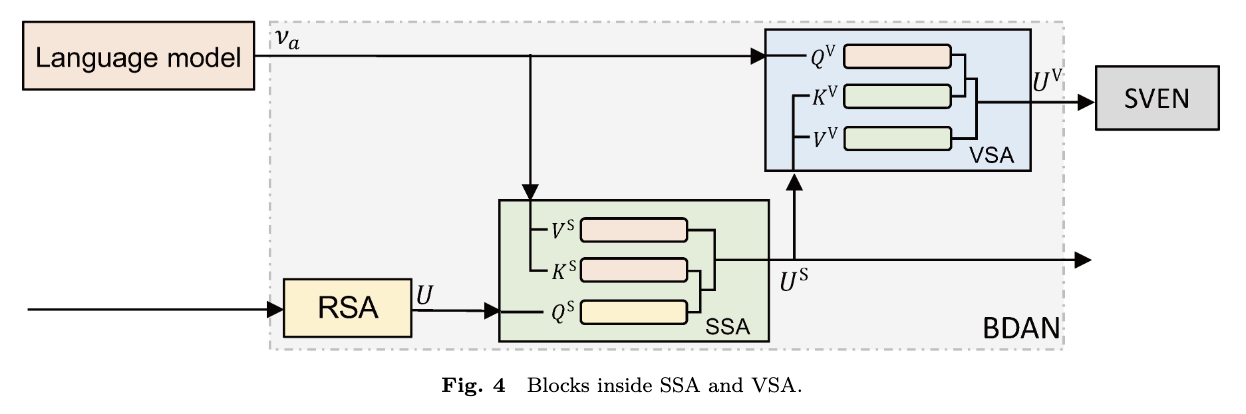
구조적 의존성: VSA(Visual Synthesis Attention)는 SSA(Semantic Synthesis Attention)의 결과물을 재료로 사용 (SSA가 선행되어야 성능이 높아짐) [Recall] SSA -> VSA 흐름
SSA
- 시각적 특징을 Query로 하여 속성(Value)와의 어텐션을 거칩니다.
- 원본 시각적 특징에 어텐션 계산 결과를 더해 속성에 해당하는 부위를 부각하는 정제된 시각 이미지를 만듭니다.
- $U^S = U + Z^S$
VSA
- 이 정제된 시각 이미지를 Value로 하여, 원본 속성(Query)과 어텐션을 거칩니다.
- 어텐션 계산 결과를 현재 속성 $\mathcal{V}_A$에 더해주며 이는 속성 정보를 업데이트하는 효과를 냅니다.
- $U^V = \mathcal{V}_A + Z^V$
중간 결과물을 계속 누적하는 것으로 보아 어텐션 결과를 ‘합성’한다는 표현이 잘 어울리고 마치 정규화항과 여러 손실함수를 더해 하나의 손실함수로 만드는 과정같기도 합니다.
다소 신기했던 부분은(그러기에 처음에 무진장 헷갈렸던) 서로 다른 모달리티에 대해 어텐션 결과를 구분하지 않고 ‘합성’했다는 점입니다. visual을 query로 하여 얻은 어텐션 맵과 semantic을 query로 하여 얻은 어텐션 맵을 이유는 모르겠지만 ‘당연히 둘은 분리해야지!’ 생각으로 읽었다가 시간만 지체했네요 .. 어쨋든
또 눈여겨 볼 부분은 VSA보다 선행되는 SSA입니다. 실험적으로 SSA가 선행될 때 유의미한 성능 향상을 보인다고 합니다.
가장 먼저 떠오르는 원인으로 이미지 chunk와 속성 chunk 간 불균형한 규모가 떠올랐습니다. 이미지가 쿼리인 경우 쿼리가 바라봐야 할 key의 가짓수가 적으니(예시로 등장한 속성은 약 3-4 단어 정도) saliency map을 만들기가 비교적 수월하지 않았을까 합니다. 반대로 속성이 쿼리였다면 속성 중심 어텐션 결과 안에 모든 이미지 chunk의 특징이 응집되게 되므로, 집중했어야 할 이미지의 시선도 분산되기 쉬워 보이네요!
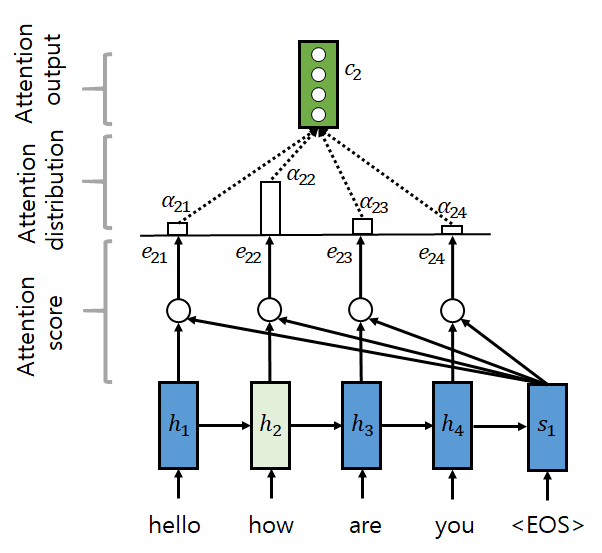 그리고 이미지(차원: HWxC) 쿼리와 속성(AxC) 키를 어텐션했을 때 왜 결과가 HWxC지? 머리가 막막했는데요 네 그냥 어텐션 매커니즘 까먹은 1인이었습니다 .. (복습하자!)
그리고 이미지(차원: HWxC) 쿼리와 속성(AxC) 키를 어텐션했을 때 왜 결과가 HWxC지? 머리가 막막했는데요 네 그냥 어텐션 매커니즘 까먹은 1인이었습니다 .. (복습하자!)
속성을 쿼리로 어텐션할 경우 한 속성 쿼리에 대해 모든 이미지 청크 키와의 유사도를 구하게 됩니다. 이때 이미지 청크 갯수만큼의 attention score가 나오게 되고 softmax 등의 함수를 거쳐 어텐션 스코어에 대한 확률분포(attention distribution)를 만듭니다. 그리고 어텐션 스코어의 기댓값이 그 쿼리에 대한 attention output이 되는데, attention distribution를 이용해 attention score를 가중합하면 attention score의 기댓값, 즉 우리가 구하고 싶은 어텐션 결과를 얻을 수 있습니다.
각 속성 쿼리마다 하나의 어텐션 결과를 얻으므로 최종 어텐션 결과는 AxC 형상을 갖게 됩니다!
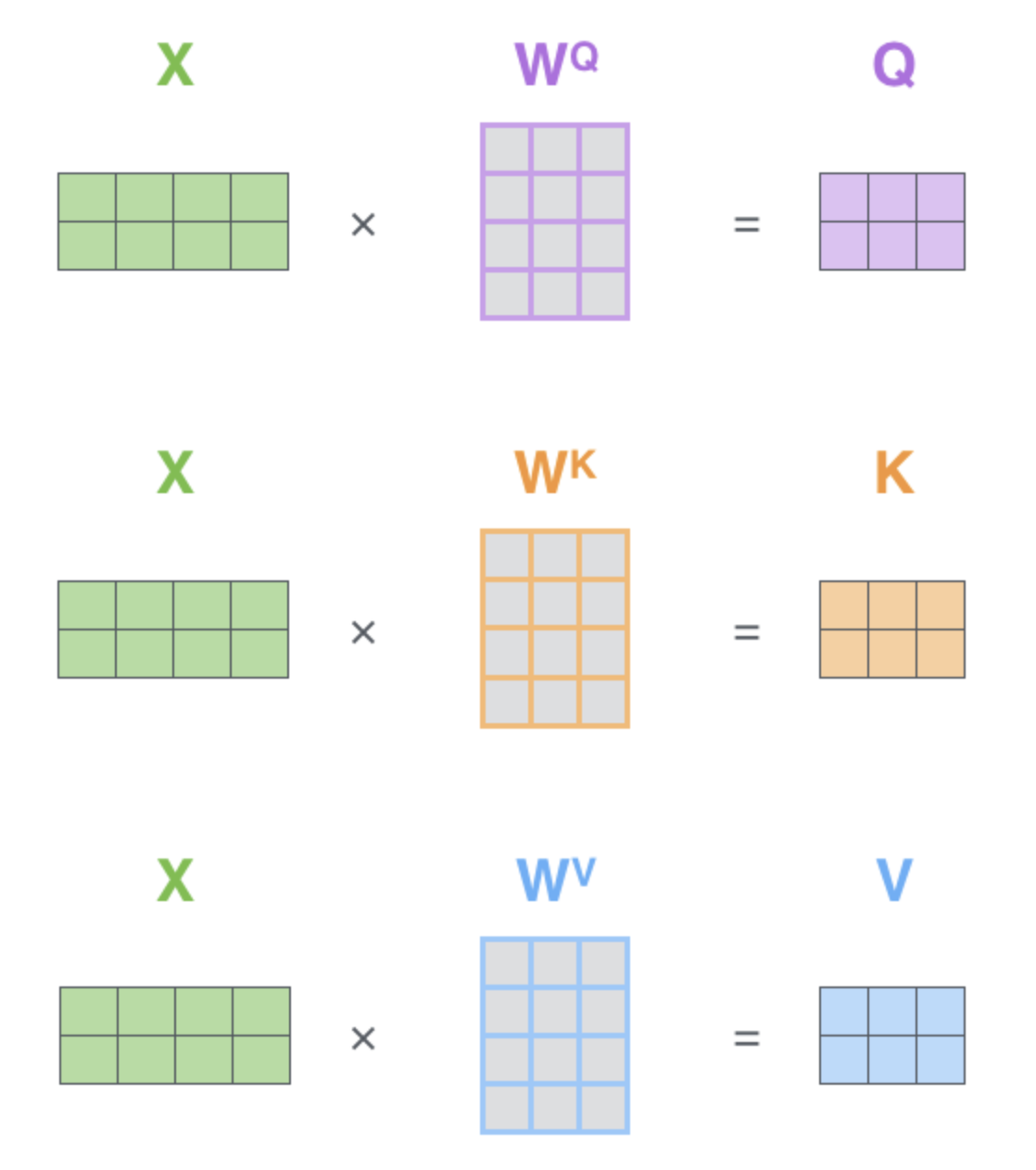
또 어텐션이 수행되는 SSA, VSA 블록은 Q,K,V로의 변환을 위한 학습가능한 가중치 행렬이 존재합니다. 역전파로 VSA의 $W^Q$를 업데이트하는 건 모델의 속성이해능력을 향상시키는 셈입니다. 참고로 제로샷 학습(ZSL)의 최종 목적은 이미지 정보를 의미 공간(Semantic Space)으로 옮겨와 분류하는 것입니다.