Autoencoders and VAE
베이즈 정리와 사후확률
사후확률분포는 관측 데이터 $D$가 주어졌을 때 파라미터 $\theta$가 따르는 확률분포다.
\[p(\theta \mid D) = \frac{p(D \mid \theta)\, p(\theta)}{p(D)}\]- $p(\theta \mid D)$: 사후확률분포(posterior). 데이터를 본 뒤의 $\theta$에 대한 분포
- $p(D \mid \theta)$: 우도(likelihood). $\theta$가 주어졌을 때 데이터 $D$가 관찰될 가능성
- $p(\theta)$: 사전확률분포(prior). 데이터를 보기 전 $\theta$에 대해 가지고 있던 가정
- $p(D)$: 증거(evidence). 전체 데이터의 확률이며, 정규화 상수 역할
 출처 : https://mbernste.github.io/posts/vae/
출처 : https://mbernste.github.io/posts/vae/
Variational Inference
변분 추론이란? : 어려운 확률 계산 문제(Inference)를 풀기 쉬운 최적화 문제(Optimization)로 바꾼 것이다. VAE에서는 사후확률분포와 같은 복잡한 확률을 계산할 때 복잡한 적분을 수행하는 대신 인코더라는 신경망을 학습시킴으로써 유사한 분포를 찾는다. 즉 인코더의 주 역할은 변분 추론을 수행하는 것이다.
$p(z)$ : 잠재 변수의 사전 분포 (Prior)
항상 표준 정규 분포를 가정하는데 이는 계산을 용이하게 한다.
참고로 가우시안 분포는 평균과 분산이 고정된 분포에 대해 가장 적은 정보를 담은, 즉 불확실성이 가장 큰 분포다. 이는 데이터에 대한 사전 정보가 없을 대 선택하기 좋은 가장 편향되지 않은 분포라고 할 수 있다. 또한 가우시안 분포는 모든 데이터가 0 근처에 적당히 모이게 강제함으로써 규제가 없을 때보다 밀도 높은 분포를 만들 수 있고 이는 새로운 데이터를 생성할 때 연속적이고 매끄러운 생성을 가능하게 한다.
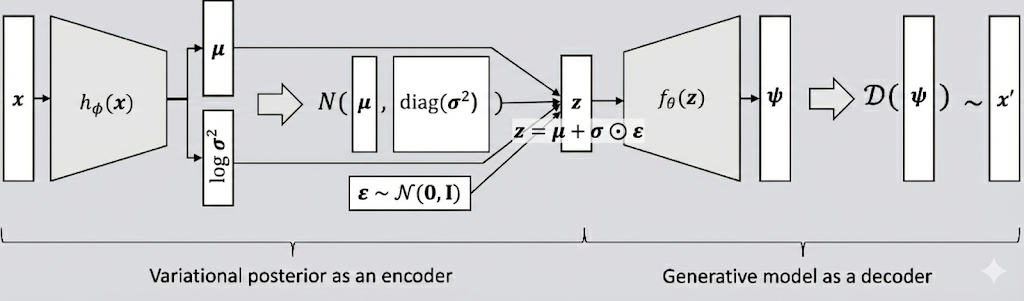
$q_\phi(z|x)$ : encoder (Approximate Posterior)
계산할 수 없는 진짜 사후분포 $p(z|x)$를 대신하여, 입력 데이터 $x$를 잠재 공간 $z$로 매핑하는 근사 분포를 학습하는 신경망이다. 인코더는 사실상 디코더가 학습을 잘 할 수 있도록 적절한 잠재 변수 $z$를 제공하기 위해 도입된 보조적인 역할을 수행한다.
$p_\theta(x|z)$ : decoder (Likelihood)
인코더가 추출한 특징 $z$를 바탕으로 실제로 데이터를 생성해내는, 생성 모델로서의 본질적인 기능을 담당한다. 즉, VAE의 디코더 $p(x|z)$는 잠재 변수 $z$가 주어졌을 때 데이터 $x$가 나올 확률을 모델링하는데, 이때 디코더의 출력 분포를 가우시안 분포로 가정한다.
\[p(x|z) = \mathcal{N}(x; \mu(z), \sigma^2 I)\] \[\log p(x|z) = \log \left( \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left( -\frac{\|x - \mu(z)\|^2}{2\sigma^2} \right) \right)\] \[\log p(x|z) = -\frac{1}{2\sigma^2} \|x - \mu(z)\|^2 - \text{constant}\]여기서 $|x - \mu(z)|^2$ 부분이 바로 입력 데이터 $x$와 재구성된 데이터 $\mu(z)$ 사이의 거리를 제곱한 값, 즉 $L_2$ 노름의 제곱이 된다.
일반적인 이미지처럼 연속형 데이터는 가우스 분포를 가정하며, 이진 데이터의 경우 베르누이 분포로 가정하여 이때는 손실 함수가 L2가 아닌 binary cross entropy를 사용한다.
Evidence Lower Bound
ELBO는 데이터 로그 확률 즉 $\log p(x)$의 하한선이자 VAE에서 학습하는 목적 함수(loss function)다.
\[\log p(x) = \text{ELBO} + KL(q(z|x) \| p(z|x))\]여기서 KL항이 언제나 0보다 크거나 같으므로 $\log p(x)$는 항상 ELBO보다 크거나 같다.
\[\text{ELBO} = \underbrace{\mathbb{E}_{q(z|x)} [\log p(x|z)]}_{\text{① Reconstruction Term}} - \underbrace{KL(q(z|x) \| p(z))}_{\text{② Regularization Term}}\]Reparameterization Trick
출력된 $\mu, \sigma$와 무작위 노이즈 $\epsilon$을 결합해 잠재 벡터 $z$를 샘플링한다.
$z = \mu + \sigma \odot \epsilon$
출처 : https://mbernste.github.io/posts/vae/
VAE Training and Inference
인코더와 디코더를 동시에 학습시킴으로써 입력 데이터를 가장 잘 설명하는 잠재 공간을 구축하는 것을 목표로 한다.
추론의 경우 생성 작업만 한다면 인코더를 더 이상 거칠 필요는 없다. ELBO 규제항을 통해 잠재 공간이 표준 정규 분포 근처에 자연스럽게 형성된 상태다. 다만 특정 이미지를 넣어 비슷한 이미지를 복원하고 싶을 때는 추론 단계에서 인코더를 사용하기도 한다. 예를 들어, 숫자 4 이미지가 인코더를 거쳐 잠재 공간에 한 점으로 투영되면, 그 근처 점들로부터 각기 다른 형태의 4 이미지를 추출할 수 있다.
참고로 잠재 공간에서 샘플링하는 $z$는 보통 N차원 이상의 길이를 가진 벡터로, 이는 이미지의 한 픽셀이 아니라 이미지 전체의 특징을 압축적으로 표현한다.
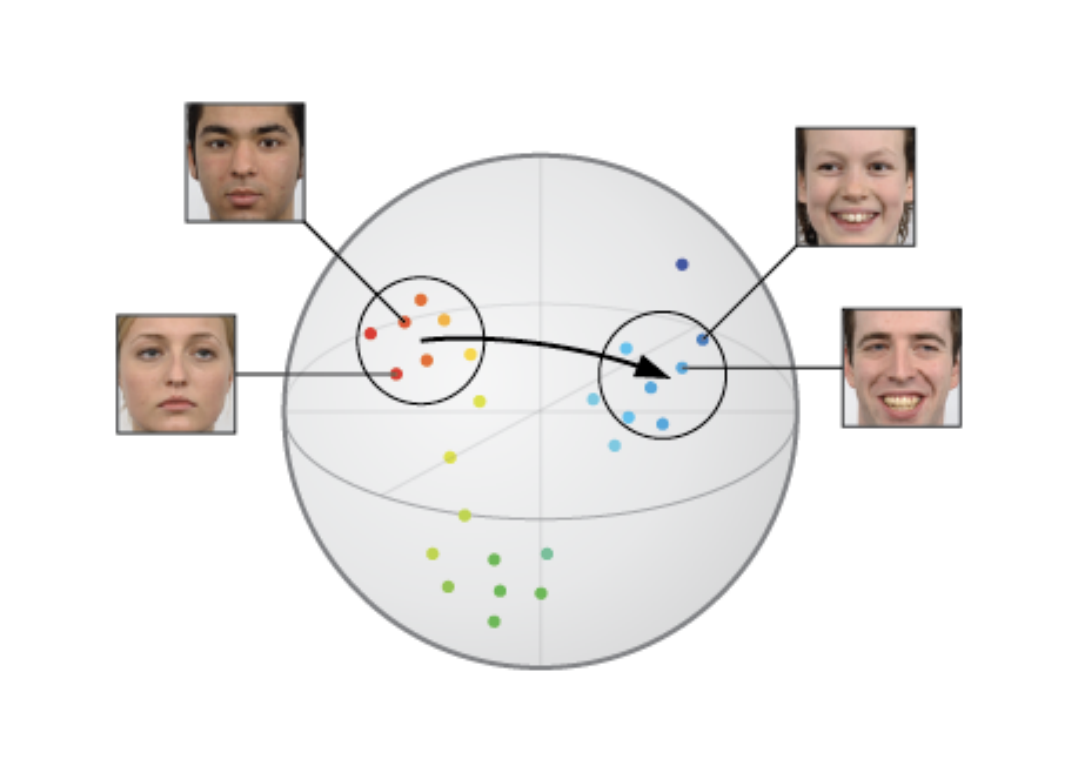
일반적인 오토인코더와 달리 VAE는 잠재 공간을 연속적이고 밀도 있게 학습하는데 두 잠재 공간 점들 간 convex interpolation을 수행하여 두 점들의 특징을 골고루 섞은 데이터를 얻을 수 있다.
\[z_{\alpha} = (1 - \alpha)z_1 + \alpha z_2, \quad (0 \le \alpha \le 1)\]이는 VAE가 KL-Divergence를 통해 잠재 공간이 표준 정규 분포를 따르도록 규제한 덕분이며 따라서 $z_1$과 $z_2$ 사이의 어떤 점을 찍어도 디코더는 의미 있는 이미지를 생성할 수 있다. 예를 들어, 무표정한 얼굴($z_1$)에서 웃는 얼굴($z_2$) 사이의 점들을 디코딩하면, 입꼬리가 점점 올라가는 중간 단계의 얼굴들을 생성할 수 있다.