Constructed EgoVLA training data incorporating physical constraints
Related posts
🛠️ Writing in progress 🛠️
Human egocentric video pre-processing
Frame Sampling
- 3 FPS로 영상 프레임 샘플링 및 384 * 384 규격으로 리사이징합니다.
- 영상은 대게 10초 이내이므로 3 FPS 적용시 27-28개의 프레임이 추출됩니다.
Hand Pose Estimation (HaMeR)
- Setup Detector (ViTDet) & Keypoint Detector (ViTPose) : MANO 파라미터를 추출하는데 필요한 hand, keypoint 탐지 모듈을 실행합니다.
- Run HaMeR : ViT로 추출된 손 정보에 대해 HaMeR를 수행해 MANO 파라미터를 추출합니다.
- Extract MANO PCA components : 추출한 45차원 MANO 파라미터는 기존 MANO 모델(.pkl)에 상수로 정의되어 있는 hands_components, hands_mean로 후처리되어 15차원 MANO 파라미터로 변환합니다.
Visualization
- 각 프레임마다 손을 잘 인식하는지 시각적으로 확인하기 위해 프레임별로 HaMeR가 만든 mesh 파일을 가져옵니다.
Hand mesh extraction (HaMeR)
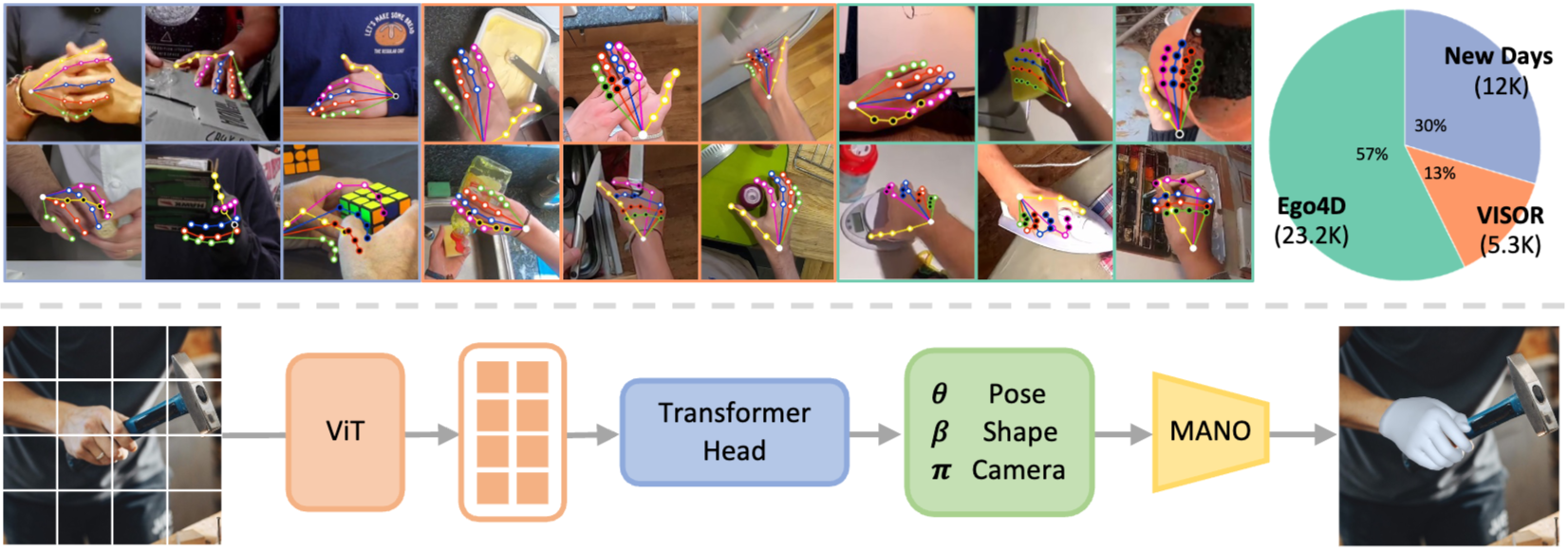
HaMeR는 2D 이미지로부터 3D 손 메쉬를 복원하는 라이브러리로 전처리된 영상 데이터로부터 MANO 파라미터를 추출하기 위해 활용되었습니다.
- Vision Transformer (ViT) 백본
- Transformer Decoder로 pose(손의 15개 관절의 3D 회전값과 손 전체의 전역 회전값, $\theta \in \mathbb{R}^{48}$), shape ($\beta \in \mathbb{R}^{10}$), camera($c \in \mathbb{R}^{3}$) 파라미터 예측합니다.
- 사전 학습된 손 모델 MANO에 파라미터가 입력되어 3D 메쉬를 생성합니다.
- 학습 시에는 예측된 3D 메쉬가 정답과 얼마나 차이 나는지 계산하여 모델을 업데이트합니다.
- 2D Reprojection Loss : 3D 관절 위치를 2D 이미지 평면으로 투영한 뒤 두 좌표에 대해 $L1$ Loss를 계산합니다.
- 3D Loss

HaMeR는 vision transformer와 MANO 모델을 결합한 프레임워크로 물체에 의한 가려짐에 더욱 강건했고 mesh를 주어진 구도와 다른 구도에서도 보여줬습니다. 측면에서 바라본 mesh를 통해 숟가락이 들어갈 공간을 잘 추측했는지 확인할 수 있었습니다.
Object mesh extraction
- TRAM (Joint Estimation)
- VCL
- SAM (Segmentation) + Depth Anything (Depth Estimation)
Physics-based refinement
Heuristic estimation of contact area
\[L_{\text{contact}} = \sum_{v \in \text{Candidates}} \left( \text{Distance}(v, \text{Object}) \right)^2\]- 손 메쉬의 모든 정점과 물체 메쉬 표면 사이의 최단 거리를 계산합니다. 이때 물체 표면과 가까운 손가락 끝 정점들을 찾은 뒤, 이 정점들이 물체 표면으로 달라붙도록 유도하는 L2 거리 손실을 부여합니다.
- 특정 임계값 이내에 있는 손 정점(Contact Candidates)들만 추출합니다.
- 단순히 가까운 점만 당기면 손등이나 관절의 어색해질 수도 있다고 하는데 실제 물체를 잡는 지점을 하드코딩하는 방법도 있습니다.
Loss for optimization
ContactOpt: Optimizing Contact to Improve Grasps (CVPR 2021)
- MANO hand mesh 기반
- 접촉 면적 예측을 위해 신경망 DeepContact를 훈련시키지만 vram 한계로 휴리스틱 방법을 1차적으로 사용했습니다. (추후 학습 예정)
위 수식은 ContactOpt에서 제시한 최적화 손실 함수입니다. 수식은 총 세 개의 손실항으로 구성되어 있습니다.
Penetration Loss
\[E_{\text{pen}}(P) = \sum_{i} \max\left(0,\; \left( v_{i}^{O} - v_{j}^{H}(P) \right) \cdot n_{i}^{O} - c_{\text{pen}} \right)\]논문 설정대로 손 정점이 물체 내부로 2mm 초과하여 들어간 거리의 합을 계산합니다.
Object Contact Loss (휴리스틱 접점 추정 단계와 중복)
\[E_{O}(P) = \sum \begin{cases} \lambda \left( \hat{C}_{O} - C_{O}(P) \right) & \text{if } C_{O}(P) < \hat{C}_{O} \\ C_{O}(P) - \hat{C}_{O} & \text{otherwise} \end{cases}\]허공에 붕 뜬 상황과 물체를 살짝 파고든 두 상황을 다룹니다. penetration loss은 비이상적인 뚫음(이 정도까지 살을 파고들지마~)에 대한 제약이고 object contact loss는 물체를 잡을 때 일부러 살을 약~간 파고들도록 만듭니다. 3D 메쉬는 기본적으로 고정적이기 때문에 이런 제약을 고려합니다.
Hand Contact Loss
손 표면을 기준으로 계산한 접촉 손실입니다. 닿아야 하는 손 부위에 실제로 닿았는지 확인하는 역할을 합니다.
새롭게 추가한 항 (후보)
\[\mathrm{MSE}(\theta, \theta_{\text{initial}})\]- Regularization Loss : 원래 HaMeR가 예측했던 초기 포즈에서 크게 벗어나지 않도록 강제합니다.
또한 물체와 손 사이 거리 제약을 위해 사용할 수 있는 또 다른 형태로
\[L_{\text{contact}} = \sum_{v \in \text{Candidates}} \left( \text{Distance}(v, \text{Object}) \right)^2\]를 어떤지 실험해봐도 좋을 것 같습니다.
.npz 파일
학습 데이터를 구성하는 카메라 위치, 손목 위치, MANO 파라미터 등은 모두 모아 .npz 파일로 관리되었습니다. .npz는 pickle과 비교해 최적화에 용이한 점 덕분에 가중치 저장을 위한 확장자로도 많이 쓰인다고 합니다.

- global_orient_rotmat = wrist rot
- translation = wrist trans
- theta = MANO pose parameters = hand pose
npz vs. pickle
.npz 파일은 NumPy에서 제공하는 배열 중심 직렬화 포맷으로, 내부적으로는 여러 개의 .npy 파일을 ZIP 컨테이너로 묶은 구조를 가집니다. 각 .npy 파일은 배열의 dtype, shape 등의 메타데이터와 실제 데이터를 연속적인 바이너리 블록으로 저장하며, .npz에서는 이를 key-value 형태로 관리합니다. 이 방식은 Python 객체 그래프를 직렬화하는 것이 아니라 순수한 수치 데이터(ndarray)를 그대로 보존하는 데 초점을 맞추기 때문에, 디스크 입출력 시 불필요한 해석 과정이 없고 메모리 매핑이나 빠른 로딩이 가능합니다.
반면 .pickle은 Python의 범용 직렬화 프로토콜로, 리스트, 딕셔너리, 클래스 인스턴스 등 임의의 Python 객체 그래프 전체를 재귀적으로 직렬화할 수 있습니다. 이는 유연하지만, 내부적으로 객체 구조를 재구성하기 위한 opcodes 기반의 직렬화 포맷을 사용하기 때문에 언어 및 실행 환경에 강하게 종속적이며, 로딩 시 Python 인터프리터가 객체를 재생성해야 하므로 .npz보다 오버헤드가 크다는 단점이 있습니다.
Further Experiement Plan
추가적인 후보 모션 선정
- DataMIL 프레임워크를 사용한 HoloAssist 데이터셋 샘플링 : HoloAssist 데이터셋은 노이즈 샘플 비중이 높아 논문에서도 전체의 1/10만 활용했었습니다. 보상 예측 기반 데이터 샘플링 프레임워크를 사용했을 때 데이터 큐레이션에 있어 더 객관적인 샘플링이 기대됩니다.
- Opening the Vocabulary of Egocentric Actions는 novel action을 근거로 임의로 선정한 후보 액션들의 novelty 평가 후 선별합니다.
- LATENT ACTION PRETRAINING FROM VIDEOS에서 사전학습된 코드북와의 거리를 점수로 낮은 점수의 액션들을 선별합니다. ✅ oulier 추출을 위해 액션을 코드북으로 사용한 연구들을 참고함.
- long-tail 현상에 입각해 물체에 다가가는 동작보다 물체를 잡은 구간에 샘플링 빈도를 높임 -> 추출된 npz 값 평균을 기반으로 kinematic score를 산출합니다.
- dynamic time warping으로 핵심 손동작에 프레임을 집중적으로 할당합니다.
Challenge
- 숟가락 잡기의 경우 사람마다 동작이 조금씩 달라 분산이 클 것으로 예상됩니다.
- 숟가락을 잡는 순간에 집중적으로 프레임을 할당하는 샘플링 전략을 취했는데 영상의 해상도 그리고 노이즈에 취약할 수 있습니다.
VLA의 long-tail 문제
long-tail 문제는 VLA 분야에서 등장하는 대표적인 데이터 편향 현상입니다. 전체 데이터 중 큰 분포를 차지하는 동작을 head action, 상대적으로 적은 비중을 차지하는 동작을 tail action으로 일컫습니다. VLA는 규모가 큰 head 동작에 과적합되는 경향이 있는데, tail의 상당 부분들이 미세하고도 중요한 움직임이 많아 문제가 된다고 합니다. 단순한 action binning 또는 VQ-VAE로 인한 미세한 조작 정보 손실 역시 tail을 향한 문제점입니다.
미세한 조작 정보 손실을 다룬 두 논문은 다음과 같고, Issac Sim에서 ‘숟가락 잡기’ 실험을 진행할 때 참고해볼 듯 합니다.
- FAST: Efficient Action Tokenization for Vision-Language-Action Models
- VQ-VLA: Improving Vision-Language-Action Models via Scaling Vector-Quantized Action Tokenizers