Maximum-Mean-Discrepancy (MMD) clearly explained!
🛠️ Writing in progress 🛠️
maximum mean discrepancy : 두 확률 분포 차이를 정량화하기 위한 지표 중 하나로, 재생 커널 힐베르트 공간(Reproducing Kernel Hilbert Space)에서 분포의 평균 임베딩 차이를 비교 kernel function : 입력 공간의 데이터 포인트를 고차원 공간으로의 점으로 변환하는 함수
- 가우스 커널
- 다항식 커널
MMD clearly explained


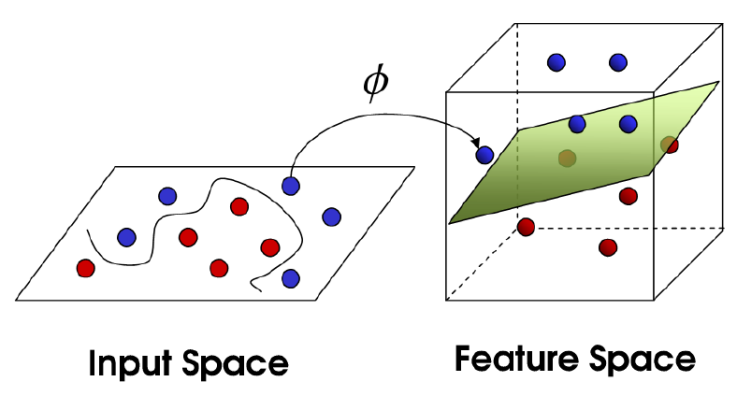 데이터 분석시 낮은 차원에서는 선형분리할 수 없는 복잡한 분포를 마주할 때가 있습니다. 이를 해결하기 위해 낮은 차원의 데이터 포인트를 고차원 공간의 점으로 매핑하게 되는데,
데이터 분석시 낮은 차원에서는 선형분리할 수 없는 복잡한 분포를 마주할 때가 있습니다. 이를 해결하기 위해 낮은 차원의 데이터 포인트를 고차원 공간의 점으로 매핑하게 되는데,
- 차원 증가에 따른 계산 비용 증가
- 어떤 매핑 함수 $\phi$를 사용할지 결정하는데 어려움
크게 두 문제가 잇따르게 됩니다. 근데 우리는 두 데이터 포인트 x,y에 대한 매핑 $\phi$(x),$\phi$(y) 간 내적에만 관심이 있는 경우가 많고, 두 매핑 결과에 대한 내적을 ‘커널 함수’로 정의할 수 있습니다.
\[k(x, y) = \langle \phi(x), \phi(y) \rangle_{\mathcal{H}}\]- 원래 데이터 $x$를 고차원 공간의 점(함수)인 $\phi(x)$로 보냅니다.
- 그 공간에서 두 점의 유사도를 구하고 싶은데, 고차원이라 계산이 너무 힘듭니다.하지만 RKHS에서는 $k(x, y)$라는 간단한 수식(예: RBF 커널)만 계산하면, 그게 곧 고차원 공간에서의 내적과 같음이 수학적으로 보장됩니다.
여기서 조금 더 나아가자면 수학적으로 커널 함수가 제 역할을 하려면 Mercer’s Theorem을 만족해야 합니다.
- 대칭성 : $k(x, y) = k(y, x)$
- 양의 준정부호 : 커널 행렬(Gram Matrix)을 만들었을 때 모든 고윳값이 0 이상이어야 합니다.
이 조건이 충족되어야만 우리가 계산한 값이 “어떤 고차원 공간에서의 내적”이라는 통계적 의미를 가질 수 있습니다.
커널 함수에는 여러 종류가 있으며 함수 종류에 따라 데이터 분포에서 반영할 모먼트, 데이터의 특징들이 달라지므로 커널 함수 선정은 중요한 문제입니다.
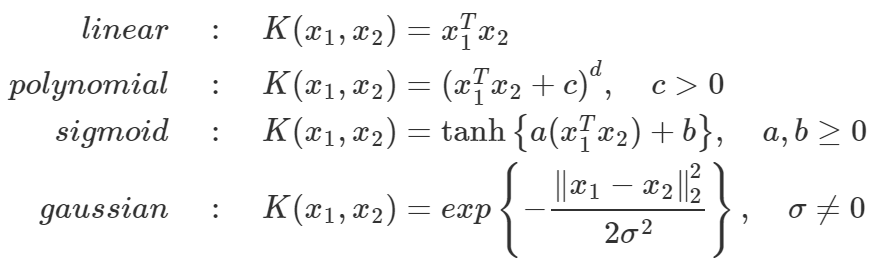 => 커널함수 종류
=> 커널함수 종류
가우시안 커널 수식에 포함된 exp()는 아래 식과 같이 지수 함수의 테일러 급수 형태를 띄게 됩니다. 이때 저차원 데이터 포인트 x에 대해 x에 대한 1차식부터 무한차수까지 다루므로 모든 모멘트를 반영하는 커널 함수가 된 셈입니다. (1차식은 평균이라는 모멘트, 2차식은 분산이라는 모멘트 등등) 참고로 꼭 가우시안 분포가 아니더라도 exp()가 포함된 커널 함수라면 자동적으로 모든 모멘트를 반영한 커널 함수가 됩니다.
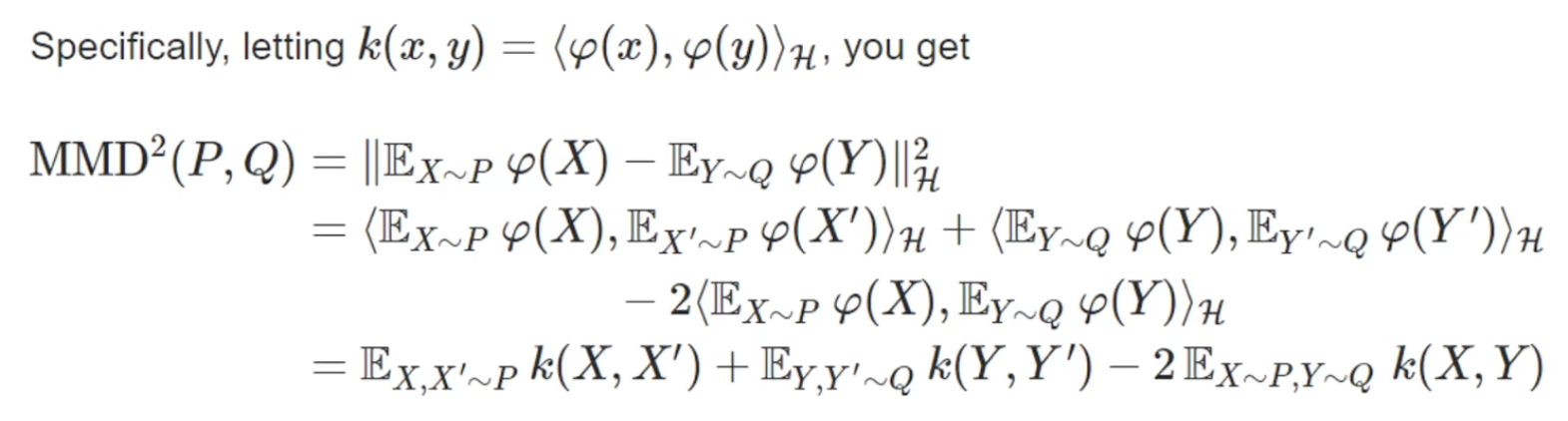
- 저차원 공간에서의 평균: 단순히 숫자들의 중간값이라서 정보 손실이 큽니다.
- 고차원 공간(RKHS)에서의 평균: 데이터의 분산, 왜도(Skewness), 첨도(Kurtosis) 등 분포의 모든 통계적 특징이 이 ‘무게 중심’ 점 하나에 압축되어 저장합니다. 이때 분포끼리 비교하지 않고 평균을 내어 점끼리 거리를 재는 이유는 거리 계산의 편의성을 위해서라고 하네요.
- mue의 유클리드 거리로 표현된 식이 시사하는 바는 특정 분포의 여러 모멘트 성질들을 고차원 공간 상의 ‘한 점’으로 표현할 수 있다는데 있습니다.
확률 분포 P,Q 사이의 MMD는 수학적으로 위와 같이 정의되며, 한 줄로 풀자면 두 확률분포를 대표하는 각각의 평균 임베딩(mean embedding)의 유클리드 거리를 나타낸다고 할 수 있습니다.
\[MMD^2(P, Q) = E_{x, x' \sim P}[k(x, x')] + E_{y, y' \sim Q}[k(y, y')] - 2E_{x \sim P, y \sim Q}[k(x, y)]\]- $k(x, x’)$: 같은 분포 내 데이터끼리의 유사도 (값이 클수록 밀집됨)
- $k(x, y)$: 서로 다른 분포 데이터 사이의 유사도 (값이 클수록 두 분포가 가까움)
MMD와 힐베르트 공간
MMD의 무대는 반드시 RKHS(재생 커널 힐베르트 공간)여야만 하며 힐베르트 공간을 벗어난다면 Wasserstein distance, KL divergence과 같이 다른 종류의 거리 측도가 된다. (어렵다 ..) 힐베르트 공간의 데이터 포인트가 ‘함수’임이 고정되어 있는건 아니고 ‘수학자들은 함수 자체가 벡터로 표현가능하다고 본다’ 정도이다. 함수는 우리가 흔히 아는 벡터 중 인덱스가 무한한 벡터로 볼 수 있으며 $x=0.1$일 때 $f(0.1)$, $x=0.2$일 때 $f(0.2) \dots$ 같은 함수에서는 0.1,0.2,0.3이 인덱스, 함수값이 원소값이 된다. 일반적인 벡터와 다른 점이라면 연속함수에 대해 인덱스가 정수가 아닌 실수라는 점이다.
(난해한 힐베르트 공간 개념 .. 정리 필요)
