Shallow transfer learning for NLP (1)
The goal of domain adaptation is to modify, or adapt, data in a different target domain in such a way that the pretrained knowledge from the source domain can aid learning in the target domain. We apply a simple autoencoding approach to “project” samples in the target domain into the source domain feature space.
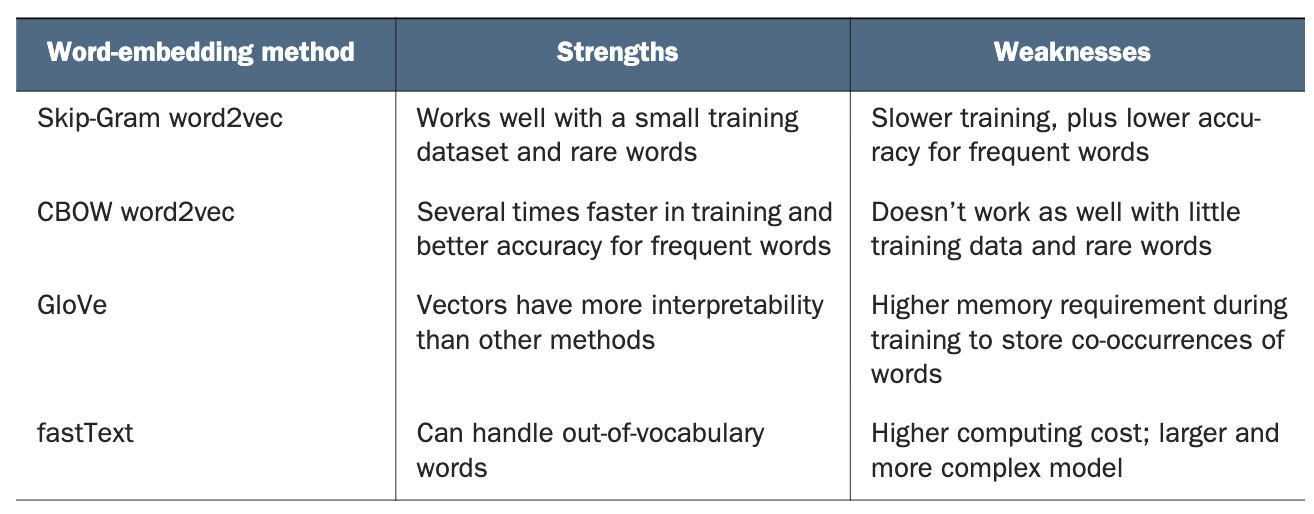
FastText is known for its ability to handle out-of-vocabulary words, which comes from it having been designed to embed subword character n-grams, or subwords (versus entire words, as is the case with word2vec). This enables it to build up embeddings for previously unseen words by aggregating composing character n-gram embeddings.
즉 word2vec은 학습 시점에 보지 못한 단어(OOV)에 대해서는 별도 벡터를 만들 수 없지만, fastText는 subword(문자 n-gram) 기반이라 새로운 단어도 그 안에 포함된 문자 n-gram 임베딩들을 합쳐 벡터를 만들 수 있다.
Multitask learning
Traditionally, machine learning algorithms have been trained to perform a single task at a time, with the data collected and trained on being independent for each separate task. This is somewhat antithetical to the way humans and other animals learn, where training for multiple tasks occurs simultaneously, and information from training on one task may inform and accelerate the learning of other tasks. This additional information may improve performance not just on the current tasks being trained on but also on future tasks, and sometimes even in cases where no labeled data is available on such future tasks. This scenario of transfer learning with no labeled data in the target domain is often referred to as zero-shot transfer learning.
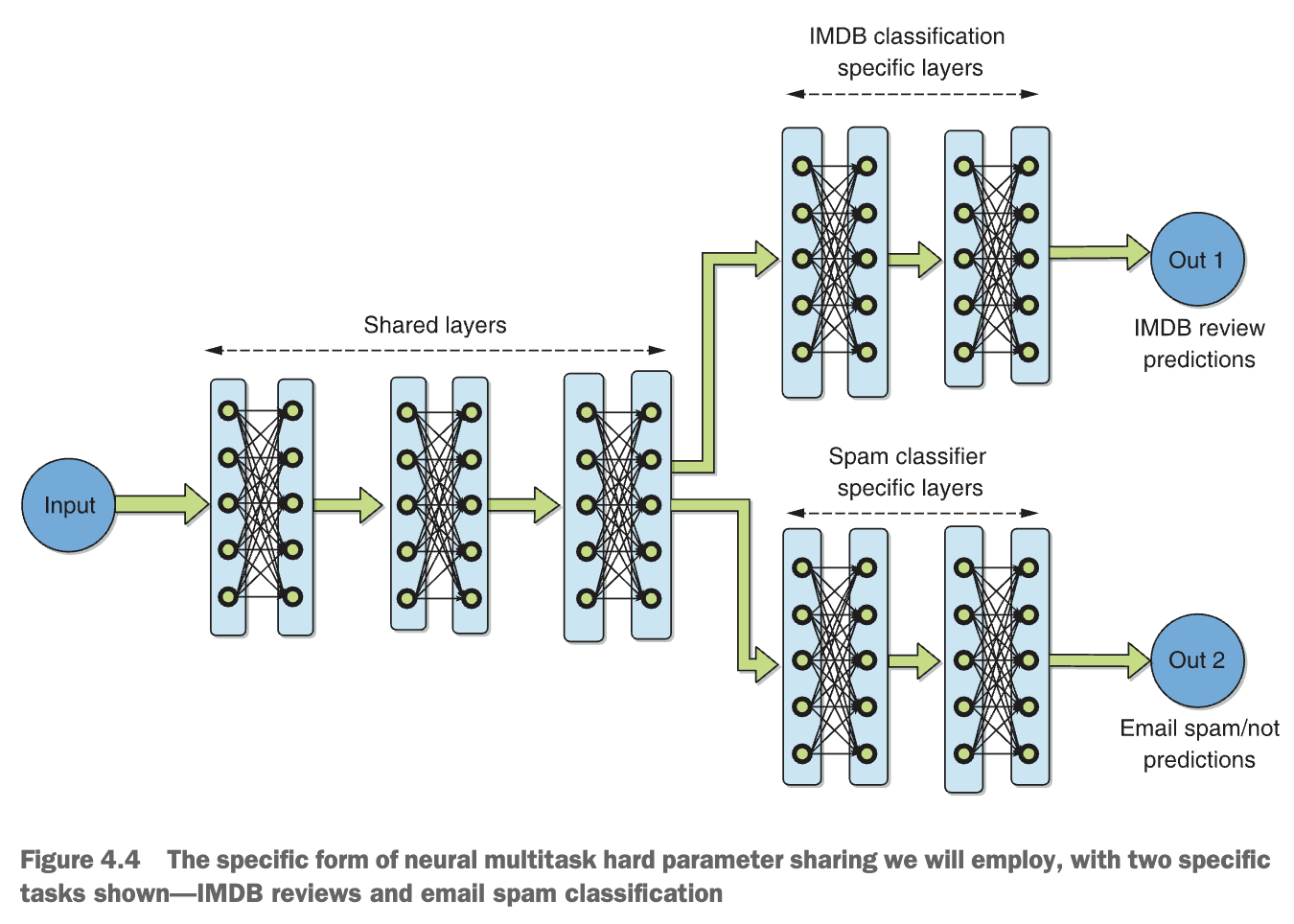
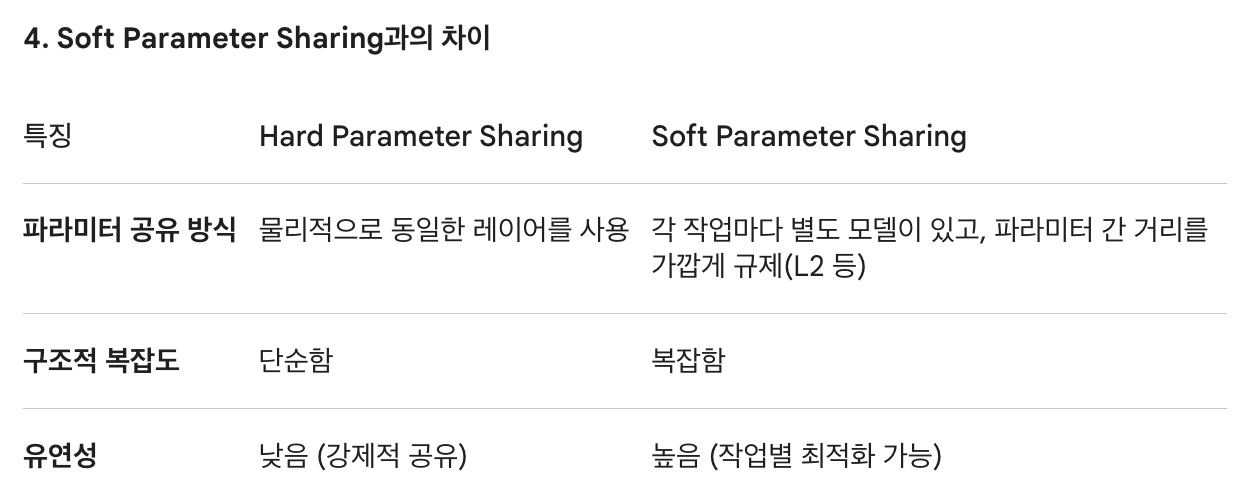 some layers/parameters are shared between all tasks, that is, hard parameter sharing. In the other prominent type of neural multitask learning, soft parameter sharing, all tasks have their own layers/parameters that are not shared. Instead, they are encour- aged to be similar via various constraints imposed on the task-specific layers across the various tasks.
some layers/parameters are shared between all tasks, that is, hard parameter sharing. In the other prominent type of neural multitask learning, soft parameter sharing, all tasks have their own layers/parameters that are not shared. Instead, they are encour- aged to be similar via various constraints imposed on the task-specific layers across the various tasks.
one-hot encoding for categorical variable representation
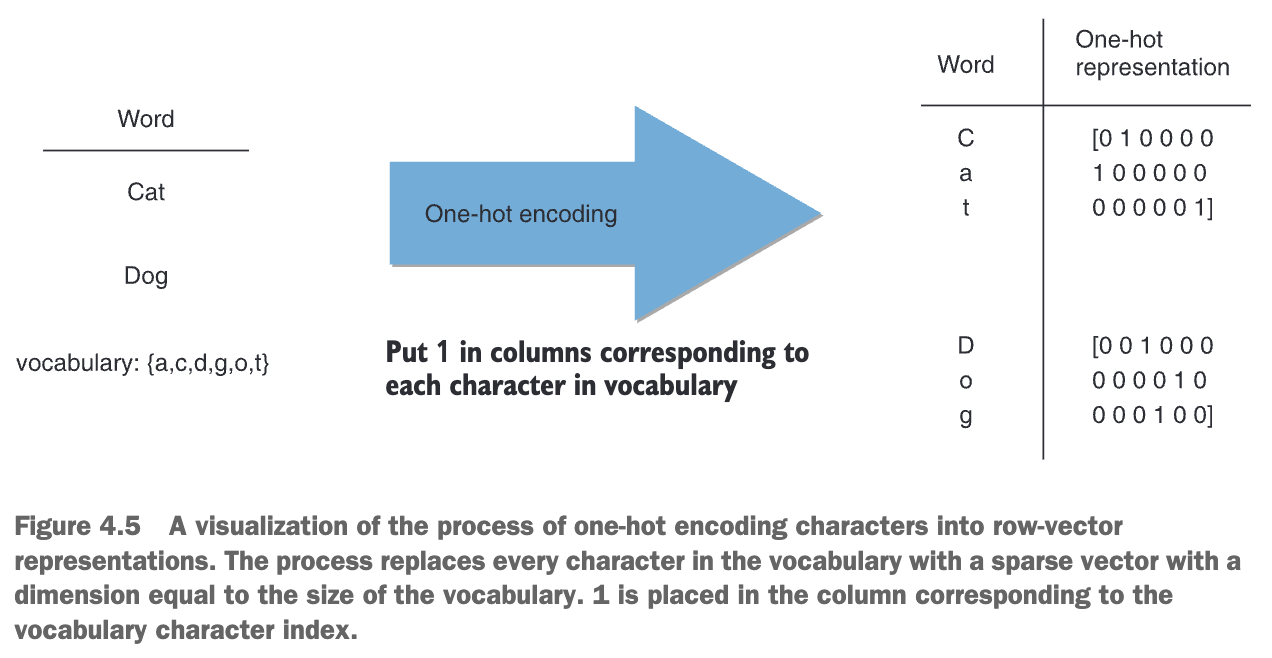 one-hot encoding can be expensive from a memory perspective, given the significant inherent increase in dimension, and as such, it is common to perform the one-hot encoding “on the fly” via specialized neural network layers.
one-hot encoding can be expensive from a memory perspective, given the significant inherent increase in dimension, and as such, it is common to perform the one-hot encoding “on the fly” via specialized neural network layers.
Processing with “on the fly” does not create huge one-hot vectors in memory in practical implementations, but holds words only as integer indexes (e.g., 42) and then allows embedding layers or special lookup layers to immediately import “ rows corresponding to that index”. (또한 가중치 행렬과 원-핫 벡터 간 곱에서 실제로 곱 연산을 할 필요 없이 인덱스를 이용해 행렬의 특정 행만 가져오는 인덱싱으로 연산 속도를 높인다)